本期主题:最近两周模型层集中爆发,GPT-5.5、DeepSeek-V4、Kimi K2.6、Images 2.0 同周登场,加上国内三家大厂同时给出的智能体工程化中文版第一性原理。
🎧 同步播客:EP37 · BestBlogs 周刊第 92 期 · 模型周(在小宇宙搜索 BestBlogs 周刊)

导语:模型层的集中爆发周
最近这两周,模型层在很短时间内接连开了几个大门。
OpenAI 发布 GPT-5.5,把模型直接定位成为自主完成多步任务设计的智能体引擎。DeepSeek 同步开源 V4 预览版,把 1M 上下文做成所有官方服务的标配。月之暗面开源 Kimi K2.6,单次运行能不间断编码 13 小时。OpenAI 还在同一周把 Images 2.0 推到了能批量生产杂志和漫画的级别。
四款一线模型挤在一起刷分,讨论的重点已经从谁更聪明,切换到了谁能让智能体在长程任务里持续可靠地干完活。
回头看前两期周刊,第 90 期我们聊的是脑和手的解耦,第 91 期是基建周,那一周 Cloudflare 把智能体云的整个栈一次补齐。这两期讲的更多是基础设施层在为智能体重新设计;本周的故事更直接,是模型能力本身在补齐基础设施之上最关键的一块。当模型变得能可靠完成多步任务,前几期看到的那些基建动作才真正有了被放大的可能性。
这一周的 20 篇精选,从模型发布到智能体工程化,再到大厂的真实采纳,几乎每一篇都在用具体动作回答同一个问题:2026 年的模型公司、基建公司、应用公司应该长成什么样子。
个人更新:BestBlogs 后续开发
这周主要在推进 BestBlogs 的后续开发和优化。
前段时间通过微信和邮件陆续邀请了 160 多位朋友来做内测,本轮邀请已经告一段落,接下来不再新增,重心会完全放在版本迭代和体验改进上。
开发过程几乎全程是 Claude Opus 4.7 写代码、Codex 做代码审查、Claude 更新文档。这套组合用下来,把这周的三件事一起跑完了:
- 开放能力发布:包括 OpenAPI v2、命令行工具,还有 BestBlogs 的 skills 包,让外部开发者可以直接调用站内数据和功能。
- 内置翻译功能上线:文章和推文详情页可以直接读译文,省掉了跳转到外部翻译网站的步骤。
- 每日回顾功能上线:补全用户的阅读闭环。
完整更新日志:https://www.bestblogs.dev/changelog
下一阶段的重点:优化个性化推荐、优化早报图文体验、优化移动端使用体验、新增话题功能、推进 App 开发。
一边在自己的产品里把开放能力做出来,一边在读阮一峰那篇关于第二次 API 开放浪潮的文章,体感会比单看新闻深一层。
一、模型层旗舰:GPT-5.5、DeepSeek-V4、Kimi K2.6 三连发
GPT-5.5:自主完成多步任务的拐点

这次 OpenAI 没有把它包装成一次聊天体验的升级,而是直接说它是为把多步任务自主完成而设计的。
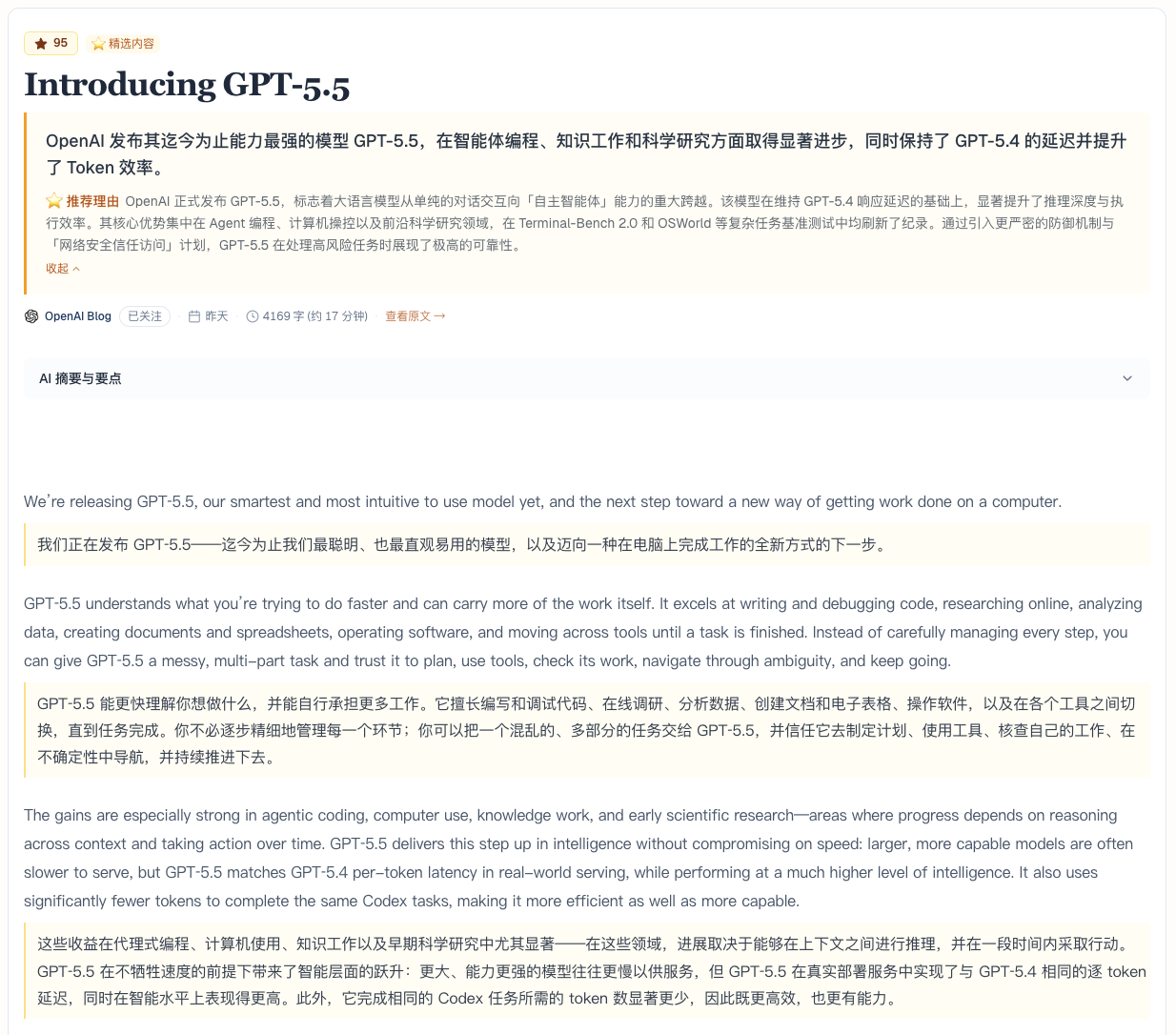
最关键的指标:延迟和 GPT-5.4 持平,但完成同样的 Codex 任务用的 token 更少。过去半年大家担心更聪明的模型一定更慢更贵,GPT-5.5 给了一个相反的答案。更聪明的同时还更高效。
OpenAI 也明确把智能体编程、计算机操控、早期科学研究列为未来的主战场。配套上线了网络安全信任访问项目,先把高风险能力关起来,在大约 200 名早期合作伙伴里做灰度。模型暂时不通过 API 全量开放。这种把能力发布和安全防护一起设计的做法,和上一期 Anthropic 推 Mythos Preview 的逻辑很像。模型公司开始接受一个事实,能力越强,红线就越要在发布前先画好。
→ 阅读原文:GPT-5.5 发布
DeepSeek-V4:1M 上下文成为标配,DSA 稀疏注意力

这版的最大动作是:把 1M(一百万)token 的超长上下文做成所有官方服务的默认配置,再也不需要用户特别开启。
技术上他们用了一种叫 DSA(DeepSeek Sparse Attention)的稀疏注意力机制,再叠加 token 维度的压缩,把长文本场景下的算力和显存开销大幅压下来。这就解决了长上下文一直以来最大的痛点,用得起但跑不动。
V4 分了两个版本:
- V4-Pro:在 Agentic Coding 上据 DeepSeek 自己内部反馈优于 Sonnet 4.5,体感接近 Claude Opus 4.6 的非思考模式,离 Opus 4.6 思考模式还有一定差距。世界知识仅次于 Gemini 3.1 Pro,数学和竞赛代码超越所有公开评测的开源模型。
- V4-Flash:为高并发与成本敏感场景准备的快速版本,简单任务和 Pro 旗鼓相当,高难度任务有差距。
V4 针对几个主流智能体框架都做了适配优化,包括 Claude Code 和 OpenClaw 这两个用户量最大的,还有 OpenCode 和 CodeBuddy 这种偏开发者的。1M 上下文加上对主流框架的开箱适配,让 V4 立刻可以接入很多现有的工作流。
一个细节:DeepSeek 的旧 API 接口(V3 时代的两个模型名)会在三个月后停用,强制大家迁移到新的 V4 命名空间。这种节奏说明 DeepSeek 把这次发布当成一个主版本切换,迭代之外还有更深的含义。
→ 阅读原文:DeepSeek-V4 预览版
Kimi K2.6:13 小时不间断编码,300 个子智能体协作

月之暗面这次直接说 K2.6 是迄今最强的代码模型,并且是开源发布。最有冲击力的是几个真实场景的数字:
- 连续编码 13 小时不间断,调用工具超过 4,000 次,迭代 14 轮
- 把一个 Mac 本地推理的吞吐量从 15 tokens/s 提到 193 tokens/s,最终比 LM Studio 还要快两成
- 对一个有 8 年历史的开源金融撮合引擎做深度重构,连续作业 13 小时,迭代 12 套优化策略,调整核心线程拓扑结构,把中位吞吐量提升将近一倍,峰值吞吐量提升一倍以上

这些都是真实跑出来的数字,不是基准测试的成绩。在博士级难度的人类最后的考试上,K2.6 也持平或优于一众顶级闭源模型,包括 GPT-5.4、Claude Opus 4.6、Gemini 3.1 Pro。在 SWE-Bench Pro 上同样行业领先。
除了单兵作战,K2.6 把智能体集群架构升级到能调度 300 个子智能体协作 4,000 个步骤。配合 OpenClaw 和 Hermes Agent 的适配,他们的强化学习基础设施团队用 K2.6 实现了连续 5 天的自主运行,模型负责监控、故障响应和系统运维。
更前沿的尝试是 Claw 群组,一个小范围内测的功能,把人和异构智能体放进同一个聊天群协作。K2.6 在中间做协调者,根据每个智能体的技能画像动态分配任务。如果某个智能体卡住,协调者会自动重新分配。这是把传统的人和工具的关系,往团队和成员的关系上推。
→ 阅读原文:Kimi K2.6 发布并开源
三大旗舰的共同信号
把这三个旗舰放在一起看,会发现一个共同信号。
过去大家比的还是单步推理的智商,现在比的是能不能把一个长任务干完。
GPT-5.5 和 Kimi K2.6 都在用同一类基准在卷,DeepSeek V4 也是在智能体框架上做适配。这其实印证了上一期广密在张小珺访谈里那句判断,编程是通用人工智能的第二幕。更深的含义是:模型公司从这周开始已经默认智能体是一个标准能力,过去那种把它当加分项的时代已经过去。任何一个新模型如果不能跑长程任务,连入场资格都没有。
还有一个信号值得提一下:这次三家发布有一个隐含的共同点,定价没有显著上升。GPT-5.5 的 token 价格和 5.4 持平,DeepSeek-V4 同价位甚至更低,Kimi K2.6 是开源免费的。在能力大幅提升的同时维持价格不变,意味着模型公司在用规模和效率消化成本,而非把成本传导给用户。这对开发者是一个好消息,用更强模型不需要重新规划预算。过去半年很多智能体应用因为成本被卡住的瓶颈,这周开始被打开了。
二、OpenAI 同周双发 + Cloudflare 简要回顾
Images 2.0:图像生成进入生产力级别

Images 2.0 是 OpenAI 把图像生成正式推到生产力级别的一次尝试。它具备了思考和联网搜索的能力,能搜实时数据再生成包含当日价格的菜单这种例子。
攻克的几个老难题:
- 精准排版
- 复杂的解释性图表
- 带完整推导过程的数学证明插图
- 多语言输出
- 成套连贯生成:一次性生成一整本结构化排版加写实摄影的杂志,或者每个房间都有独立设计的家装方案,或者一部固定角色和演进剧情的漫画
加上 2K 高清和结构化设计,Images 2.0 已经从画着玩的工具,变成一个为出版、设计、内容生产线准备的工具。OpenAI 自己把它比作图像生成领域的文艺复兴。在它之前的 DALL-E 像洞穴壁画,Images 1 像古代艺术。
→ 阅读原文:这就是 ChatGPT 图像 2.0
Workspace Agents:可重复工作流的标准化
同周的 Workspace Agents 走的是另一条路:把 ChatGPT 从一次性问答推向可重复工作流。一个智能体由三部分组成:
- 触发器(Trigger):定时(如每周一上午 10 点)或事件触发(如 Slack 表单提交)
- 专业技能(Skills):领域知识封装
- 可用的第三方工具(Tools):CRM、Slack、文档系统等
举个例子:每周一上午 10 点自动拉取营销 KPI,识别趋势,起草总结,提议下一步行动,分配责任人。和过去用 API 做的确定性工作流相比,它多了一层概率性的判断。
OpenAI 在文档里特别强调,这种东西不适合一次性的开放式思考,但很适合那些每周或每天都要做的、有明确输出格式的事情。文档里还提供了几种典型模式:营销活动总结、产品反馈分流、销售管道总结,每个模式都给出了完整的智能体拆解,包括目标、触发器、流程、工具,方便企业直接套用。它服务的是企业流程里那些固定的协作节点,和单点任务的替代工具定位完全不同。
→ 阅读原文:工作区智能体
Cloudflare Cloud 2.0 简要回顾

上一期基建周我们花了很长篇幅聊 Cloudflare 的 Agents Week,本周他们出了一篇正式的总结博客,把计算、存储、安全、推理路由这四层一周内发布的东西全部汇总,并且明确说这是智能体云的官方定调。这篇博客更像是一个回顾索引,没有新信息,对上一期漏听的朋友是一个补课的好入口。
→ 阅读原文:构建智能体云:我们在 2026 年智能体周期间发布的一切
这一周模型层和基建层完成了一次同步迭代

模型公司发的不只是更聪明的模型,发的是配套的工作流形态。基建公司发的不只是新原语,发的是面向智能体重新设计的整个云。
这种节奏在过去是少见的。基建层的迭代往往要落后模型层半年到一年,现在两边几乎是平行推进。
对个人开发者来说,这意味着接下来选型的复杂度上升了。半年前可能只需要选一个模型,现在需要同时选模型、智能体框架、基建。但好处是每一层都有更成熟的选择,不再像一年前那样什么都要自己撑起来。这周的几篇文章其实给出了一些参考组合:
- 模型:GPT-5.5 / Kimi K2.6 / DeepSeek-V4
- 框架:OpenClaw / Hermes Agent
- 基建:Cloudflare 这套
这就是一个完整的智能体工作流栈。
三、AI 编程的真实图景:三个人的视角
Garry Tan:薄 Harness、厚 Skill 的开源实践

YC 总裁 Garry Tan 三周前开源了一个项目叫 GStack,到这周它在 GitHub 上的 Star 数已经超过了老牌 Web 框架 Ruby on Rails 的总数。这个对比本身就挺有意思。
GStack 的核心理念用八个字总结:薄 Harness 厚 Skill。它做的事情是把 YC 自己最核心的工作流封装成可复用的技能。
最典型的几个 Skill:
- Office Hours:把 16 位 YC 合伙人多年总结出来的 6 个核心问题做成模板,在你写代码之前先逼你回答清楚商业模式和用户痛点。Garry 在视频里演示了一个税务 App 的例子,用户输入想法,模型先问最强有力的证据是什么,再追问 TurboTax 等已有工具为什么不能解决,最后引出一个楔子战略的判断。整个对话像在和一个 YC 合伙人面对面交流。
- Design Shotgun:对抗性设计审查技能,让 AI 用不同视角挑战你的产品方案,找出弱点。
- Playwright 测试:浏览器自动化封装成 Skill,开发完成后自动跑回归。
Garry 自己讲了一个细节:他今年写的代码已经超过了 2013 年全年。那是他最后一次作为全职工程师高强度工作的年份。当年他和联合创始人带 10 人团队、花 1,000 万美元、用 2 年时间才把 Posterous 做出来,现在他基本上一个人就能重做出来。
这条信息与其说是炫耀,更像是在说明工具正在让一个人重新具备小团队的产能。
视频里他还演示了用 Conductor 同时管理多个并行会话。一个会话在测试网页,另一个在写后端代码,第三个在调试,他只需要在中间审阅和决策。
→ 阅读原文:Garry Tan 的 Claude Code 设置内幕
Cat Wu:把发布周期从 6 个月压到 1 天

Anthropic 的 Cat Wu 是 Claude Code 的产品负责人。她在 Lenny 的播客里揭了一些 Anthropic 内部的运作细节,最让我有共鸣的是他们把发布周期从 6 个月压到了 1 天。秘诀其实非常朴素:
- 所有功能先以研究预览版形式上线,明确标注早期性质,把长期支持的承诺压力降下来。团队能在 1-2 周内就上线新想法并获取反馈。
- 长青发布室频道:工程师觉得功能成熟了就在里面发个帖,文档、市场、开发者关系等团队当天就跟进,第二天发营销公告。
- 大量招产品品味强的工程师:让工程师能直接根据推特上的用户反馈在一周内自主迭代。
Cat Wu 还分享了她和 Boris 的分工模式:Boris 负责设定 3-6 个月后的产品愿景,她负责规划从现状通往那个愿景的路径,并且在功能开发完成后清除所有发布阻碍。两个人大约 80% 的时候想法完全一致。
她还谈了 Anthropic 文化的另一个特点:团队成员都有一种拥抱混沌的特质,因为风险和变数太多,过度焦虑很快就会崩溃。Anthropic 倾向于聘用经历过行业起起伏伏的资深人士。
Cat Wu 给从业者的核心建议很犀利:
把自动化做到 100%。差一点就会成为你的瓶颈。
她举例说,Anthropic 内部有些工程师写完一个 PR 之后,会用 AI 帮他做接下来所有事情,从写测试到写文档到合并部署。这种从首次代码提交到最终上线全自动化的工作流,才是真正放大产能的路径。
这条建议听起来朴素,但联系到上面 Garry Tan 那个数据,其实是一致的:工具效率的边际收益要在最后一公里才真正显现。
→ 阅读原文:Anthropic 产品团队如何比任何人都快 | Cat Wu
Pragmatic Engineer:大厂里那个让人哭笑不得的 token 刷量

Pragmatic Engineer 的 Gergely Orosz 在 AI Engineer 大会上揭露了一个让我哭笑不得的现象,他把它叫做 Token Maxing(token 刷量)。
简单说就是大厂把员工的 AI token 消耗量当作绩效指标:
| 公司 | 操作 |
|---|---|
| Salesforce | 每个员工月均 $175 的 token 最低消费,月初不达标就要疯狂用 |
| Meta / Microsoft | 内部排行榜,工程师为了排名不垫底开始用智能体生成一堆没用的总结 |
| Coinbase | CEO Brian Armstrong 发全员邮件要求所有人必须用 AI 工具,一周后真的开除了一名没用的工程师 |
Gergely 的判断是,这种现象本质上是管理层在对工具效果还没充分验证的情况下,用强制指标推动落地。这背后有一种古德哈特定律的味道,任何被作为目标的指标都会被滥用。
他还讲了一个对比,几个月前 Token Maxing 最初还只是个玩笑,大家是为了好玩疯狂尝试用它来构建很酷的东西,但现在演变成了一种奇怪的职场文化。
访谈里 Gergely 还分享了一个更有价值的观察:大厂在内部 AI 基础设施上的投入远超外界想象。Uber 自己建了一个内部的 AI 网关,统一管理所有内部模型调用;Shopify 把内部所有 AI 工具集中到一个平台;Meta 和微软都在做自己的 MCP 网关,专门处理智能体和企业系统的对接。这些公司不依赖现成工具,而是花大力气自研。
→ 阅读原文:AI 如何改变软件工程:与 Gergely Orosz 的对话
三个视角的张力
把这三个视角放在一起看,AI 编程在 2026 年呈现出一种很微妙的张力:
- 一边是 Garry Tan 这种能用工具放大十倍生产力的真实案例
- 另一边是大厂内部因为指标焦虑产生的扭曲现象
Cat Wu 的一句话其实是一个分水岭:把自动化做到 100%。要么让工具真正改变你做事的方式,要么不要假装它在改变。
四、智能体工程化:国内三家大厂同周给出第一性原理
第四个主题,是这周国内三家大厂同时发的关于智能体工程化的中文版深度文章,加上 Anthropic 和 Addy Osmani 对智能体技术栈的押注,最后再连上 MiniMax 和 Hermes 的中美对谈。这五六篇放在一起,构成了本周智能体工程化的一个完整切片。
腾讯云:从第一性原理思考 Agentic Engineering
腾讯云开发者那篇的核心论点:把 vibe coding(凭直觉接受 AI 输出)和 Agentic Engineering 做了清晰的切分。前者将需求直接抛给 AI,不审查 diff、不理解生成的代码,凭直觉接受输出,以最快的速度得到能跑的结果。而 Agentic Engineering 代表了一种截然不同的范式,AI 不仅是代码的执行者,也是问题分析、方案设计等环节的思考伙伴,但最终的判断和决策权始终在工程师手中。
文章有一个观点我特别认同:工程的本质是约束优化,是在给定资源、时间、质量的约束下找最优解。AI 不会改变这个约束本身,它改变的是约束内的搜索效率。
文章梳理了软件工程长期以来的几大痛点:需求阶段的意图表达失真、设计阶段的知识难以沉淀、编码阶段的上下文获取成本高、审查阶段的瓶颈在人。共同根源归纳为四点:
- 信息损耗
- 知识孤岛
- 认知成本
- 组织摩擦
Agentic Engineering 的方法论是把这四个问题分别用上下文工程、规约先行、技能模块化、自我精炼这四个手段来解决。这个映射很清晰,对于想在团队内部推动 AI 工程化的人来说,可以直接套用。
作者还把这套方法论开源成了一个基于 Skill 的完整框架,包含 SDLC 工作流、最佳实践、自我精炼机制,可以直接 fork 来用。
→ 阅读原文:从第一性原理思考 Agentic Engineering
阿里 Aegis:Harness 是为非确定性引擎设计的物理控制面
阿里云开发者那篇是 Aegis 项目的复盘。作者给出了一个最锋利的定义:
传统软件工程管的是确定性,Harness Engineering 管的是非确定性。
一个 add(a, b) 函数,只要代码没 bug,结果永远确定。但大模型是概率引擎,同样的输入,它可能直接返回结果,可能调一个不相干的工具,也可能因为前文某句话幻觉暴走。所以 Harness 不是泛泛的好习惯,它是一个为非确定性引擎设计的物理控制面。
文章用两个坐标轴画了智能体架构的四象限矩阵:
- X 轴:执行流路由,从静态预设到动态自主
- Y 轴:状态,从隐式内部到显式外部
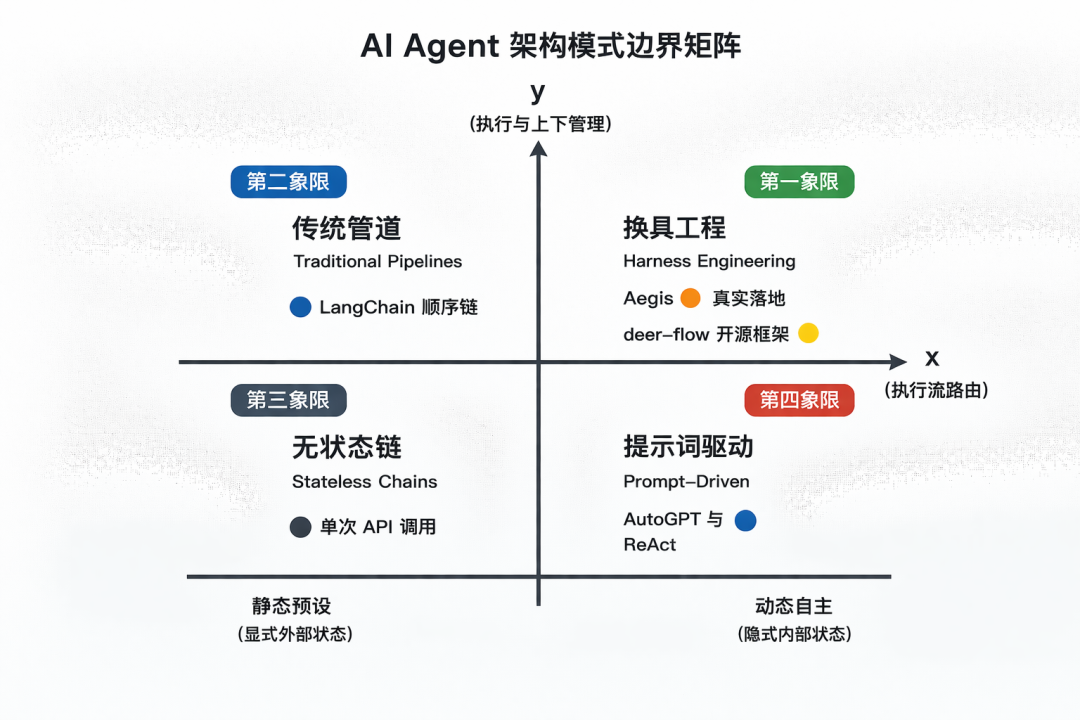
Harness Engineering 落在第一象限:模型负责意图,外部 Harness 负责状态隔离和沙盒校验。开发成本相对高,但能用合理成本换一个更稳的系统下限。
文章还戳破了几个常见的伪 Harness 现象:
- 在提示词里写 5,000 字几十条 DO NOT 这种软约束
- 把所有逻辑塞进单次对话上下文,模型之外没有任何物理约束
作者举了 Aegis 项目的真实例子:一开始他们没急着写发请求的智能体,先去读架构文档、收敛目标、迁移参考实现。推进过程中遇到了上下文断裂、工具耦合、接口报错、本地测试退出这些问题。复盘下来发现,决定能不能跨过这些坎的关键其实在 Harness 是否搭得扎实,跟换一个更聪明的模型关系不大。
→ 阅读原文:从玩具到生产力:用真实项目讲透 AI Agent 的 Harness Engineering
腾讯审核 L3:80% 效能提升的全自动化路线图

腾讯审核团队的实战总结把全自动化研发交付分成了三个阶段:
| 阶段 | 状态 | 说明 |
|---|---|---|
| L1 | 纯人工 | 传统模式 |
| L2 | 人机协同 | 2025 年所处阶段 |
| L3 | 全自动 | 2026 年目标,80% 研发效能提升 |
他们梳理了四大核心挑战:
- 交付流程的标准化
- 需求的标准化
- 知识库的标准化
- 技能(Skills)的标准化
最让我印象深的是他们提的 PRD-Agent,让产品经理在标准模板里写需求,自动按规则评分,不达标直接打回。这本质上是把工程纪律前置到需求阶段,避免下游因为需求模糊而反复返工。
文章里还分享了一个很有意思的细节:他们用大模型自动生成代码评审、自动生成测试用例、自动生成部署脚本,把整个交付链路串起来。当某一环节出问题,流程自动回滚。这种把治理和交付双轮驱动的设计思路,把传统的 DevOps 平台能力扩展成了一个 AgentOps 平台。
→ 阅读原文:从提需求到部署发布,全 AI 全自动化后,研发效能全面跃升
三篇文章的共同结论
程序员的核心价值正在从亲手写代码迁移到定义目标、卡住边界、控制节奏、做最终验收。
它和上一期那篇 Anthropic 的 Managed Agents 文章里讲的脑和手解耦其实是同一个判断的不同侧面。
Anthropic:MCP 是 M×N 集成的事实标准

Anthropic 的 MCP 实战指南给出了智能体接入外部系统的三条路径对比:
| 路径 | 适用场景 | 局限 |
|---|---|---|
| 直接 API 调用 | 一对一集成 | 规模上去后变成 M×N 集成噩梦 |
| 命令行工具(CLI) | 本地环境 | 无法触达云端服务 |
| MCP(模型上下文协议) | 多对多通用层 | 需要前期投入,回报是可移植性 |
MCP 的 SDK 月下载量已经突破 3 亿次,是解决 M×N 集成问题的事实标准。一个远端服务可以同时被多个兼容客户端复用,包括 Claude,再到 ChatGPT 和 Cursor 这些工具。
Anthropic 给出的最佳实践:按意图组织工具,不要按 API 端点组织。复杂的接口考虑用代码编排模式,让模型写一段调用代码,而非直接调一个万能工具。
→ 阅读原文:使用 MCP 构建能够接入生产系统的智能体 | Claude
Addy Osmani:Agent Stack 四大架构押注

Addy Osmani 那篇 Agent Stack 押注从架构层给出了四个判断:
- 智能体需要独立身份,不是借一个服务账户跑
- 需要通用上下文,不能每次都重新构建
- 需要持久化运行,不能每次都从零开始
- 需要标准化平台,不能每个团队都重复造轮子
文章里有一句话我觉得很值得记下来:
今天大多数所谓的生产级智能体打开机盖看,里面没有智能,只有自定义的胶水代码、脆弱的会话逻辑、共用的服务账户,还有一个靠希望维系的安全模型。
→ 阅读原文:智能体技术栈的押注
MiniMax × Hermes:中美智能体团队的对谈

Hermes Agent 是 OpenClaw 之后这个月最火的智能体框架,GitHub 上 22K+ Star。MiniMax 的首席架构师阿岛和研发工程师择因,加上 Hermes 的业务负责人 Tommy Eastman 在直播里聊了将近 3 小时。
访谈里几个判断我觉得很有冲击力:
- 模型和智能体必须一起做。靠模型公司纯训练或者智能体公司纯框架都做不出最好的产品。Anthropic 和 MiniMax 都在用行动印证这一点。
- 通用智能体终将吃掉垂直智能体。这个判断和上一期我们提到的广密的视角一致。
- 审美和目标定义将成为人类最后的护城河。当所有可被技能化的工作都被打包,剩下的就是那些需要品味判断的部分。
阿岛在访谈里还讲了一个有意思的观察:国内用户对 OpenClaw 的接受度其实比海外更高。因为国外用户之前已经接触过 Claude Code、Codex 这些好用的智能体,国内用户是被 OpenClaw 一下子捅破窗户纸的。海外是渐进式的,国内是跳跃式的。这种用户认知节奏的差异,决定了中国市场对智能体产品的需求形态会和北美不一样。
→ 阅读原文:当我们在讨论 Harness 的时候,我们在讨论什么
五、Shopify 全栈实践(本周最值得深读的一篇)

这一段我想专门给 Shopify CTO Mikhail Parakhin 在 Latent Space 那场访谈。它是这周我个人最推荐的一篇深度内容。因为它讲的是一家市值 2,000 亿美元的 20 年老公司,在 AI 时代怎么把内部全栈重新打造一遍。
Mikhail 是从微软过来的,之前负责过几个大盘业务,包括 Windows 操作系统、Edge 浏览器、Bing 搜索还有广告业务。他对 AI 的判断有一种从大公司高管视角出发的稳健感。
90%+ AI 采纳的三大支柱
Shopify 现在的内部 AI 采用率已经超过 90%,这是一家上万人规模的公司。支撑这个采用率的是三个内部系统:
| 系统 | 用途 |
|---|---|
| Tangle | 机器学习实验和数据流水线的可重复性工具,对标 Airflow 但更面向研究。实验、模型、数据从一开始就为生产环境设计 |
| Tangent | 自动科研工具,把模型优化的循环交给系统自己跑。工程师定义目标和约束,剩下的让自动化完成 |
| SimGym | 利用 Shopify 几十年积累的电商数据做顾客行为仿真,可以在虚拟环境里反复测试新功能对用户行为的影响 |
AI 时代真正的护城河,往往是私有数据和能在数据上反复模拟的能力,模型本身反倒不是壁垒。Shopify 几十年的真实电商数据,是任何模型公司都无法复制的资产。
两个让人警醒的判断
判断一:AI 编码的瓶颈已经从生成转移到 review 和发布稳定性
模型现在写代码可能比平均的人类更干净,但产品里出现的 bug 反而可能增多,因为代码审查、CI、CD 这些环节没有跟上节奏。Shopify 自己内部建了一套 PR 审查的工作流,并且认为大部分现成的 review 工具都没有抓到要点。
Mikhail 直接说:他们花在审查上的钱已经超过花在生成上的钱,这才是 AI 编码真正的下半场。
判断二:token 预算这个方向是对的,但用 token 数量评估工程产出仍然是错的
最终交付的质量、稳定性、可维护性,这些都不是 token 能量化的。
这其实直接呼应了前面 Pragmatic Engineer 那篇关于 token 刷量的文章:一边是大厂用排行榜逼员工刷 token,另一边是 Shopify 在花更大力气投资审查和发布稳定性。同样是高 AI 采用率,路径完全不同。
Liquid AI 与 CLI 工具趋势
访谈里还提到一个很有意思的细节:Shopify 在用一个叫 Liquid AI 的非 Transformer 架构做超低延迟搜索。这是为了把搜索响应控制在 20ms 以内,传统 Transformer 架构做不到这个级别。Liquid AI 是麻省理工出来的一家公司,他们和 Shopify 签了多年合作协议,专门做小型基础模型的核心商务体验落地。
这种工程取舍说明,到了真实生产规模,公司愿意为了延迟去用一些非主流架构,而非迷信通用模型。
Mikhail 还分享了一个对工程师角色变化的观察:在 Shopify 内部,命令行风格的工具上升速度比传统 IDE 风格的工具更快。因为命令行更容易被脚本化和编排进自动化流水线。这和 Cat Wu 那条把自动化做到 100% 的建议是一致的,工具形态本身在向更易自动化的方向演化。
Sydney 时代的经验带到 Shopify
Mikhail 还回顾了他在微软 Sydney 时代的经验,那是必应早期接入大模型的时候,遇到了非常多模型行为不可控的问题。他把那段经验带到 Shopify 之后,最大的体会是:AI 产品上线之前的安全测试和线上监控同样重要,不能只测一个静态的 benchmark,要做动态的对抗性测试。
Mikhail 这场访谈和前面那个 token 刷量形成了一个鲜明对照。判断哪一种更对,可能要等到一两年后看公司的产品质量和事故率。但至少从访谈里能看出来,Mikhail 思考的重心放在怎么重塑工作方式本身,token 这种表层指标对他来说反倒不是第一位的。
→ 阅读原文:Shopify 的 AI 相变 - 对话 Shopify CTO Mikhail Parakhin
六、模型公司战略:四场重磅访谈
最后一个主题,几场重磅访谈把模型公司的战略叙事彻底刷新了一遍。
Sam Altman + Greg Brockman 罕见同台:OpenAI 的重大重置

最罕见的是 Sam Altman 和 Greg Brockman 在 Core Memory 播客上的同台。这是他们很长时间以来第一次一起接受播客采访。
两个人从 2015 年那场决定创办 OpenAI 的晚宴讲起,复盘了从非营利到营利的转型、董事会冲突、Sam 那次被解雇的风波。但访谈最有信号价值的部分,是 OpenAI 这次的所谓重大重置:
- 从模型即产品转向智能体基础设施
- 为 Codex 战略性推迟 Sora。Codex 处理的是繁琐的电脑工作,是一个能让 AI 帮你完成日常的入口
- Sam 提了个人 AGI 的概念,未来每个人都有一个深度了解你上下文、能代表你执行任务的 AI
- 两个人都明确说,未来是一个由 80 亿个个人智能体驱动的计算经济
这个判断如果是对的,今天所有平台都会被重新定价。
访谈里还提了一个细节:OpenAI 现在面对的不只是产品竞争,还有大量对算力的物理需求。Sam 强调算力普惠是一个道德义务,集中在少数几家公司手里会加剧不平等。他还讲了这两年 OpenAI 经历的紧张时刻,包括一次他在自己家附近被人扔燃烧瓶的事件,以及他们正在和马斯克打的法律纠纷。但 Sam 的态度是把所有这些都看成发展中的成长烦恼,不影响 OpenAI 的核心战略。
→ 阅读原文:Sam Altman + Greg Brockman - 关于 OpenAI 的重大重置
Greg Brockman 单独:强化学习是从预测到推理的拐点

紧接着是 Greg 单独做客另一档英文播客 The Knowledge Project,主播是 Shane Parrish。这场更长,超过 2 万字,重点是他用强化学习这条主线串起了从 Dota 到 GPT-4 的整个历史。
他的核心判断:
强化学习是 AI 从预测走向推理的关键拐点。
预训练让模型学会了世界的统计规律,强化学习让模型学会了在没有明确答案的环境里探索和调整。
他还预言未来的经济会被 80 亿个个人智能体重新结构化,主导力量会是大量中等智能的智能体协作,而非几个超级 AI。
访谈里 Greg 也坦率讲了 Sam 被罢免的内部博弈,团队当时表现出的忠诚度让他至今印象深刻。绝大多数员工都签了愿意跟 Sam 一起离开的承诺书。
两场访谈对照看,Sam 和 Greg 的关系更像是早期合伙人那种相互依赖,和典型的 CEO 加总裁分工很不同。Greg 自己说他们俩平均一天通 5 次电话,每次几分钟,保持持续的同步。这种节奏是 OpenAI 这十年能在巨大压力下维持稳定的一个关键。
→ 阅读原文:OpenAI 联合创始人 Greg Brockman 谈 AI 竞赛、Sam Altman 解雇风波与 AGI 未来
罗福莉首次长访谈:后训练时代的范式转变

第三场访谈是张小珺对小米大模型团队负责人罗福莉的 3.5 小时长谈。这是罗福莉的第一次正式技术访谈。她之前供职过阿里达摩院和 DeepSeek,目前主导小米 MiMo-V2 系列模型。
她给出了几个判断:
- 2026 年大模型战争进入第二幕:从预训练主导的对话时代转向后训练主导的智能体时代
- 国内顶尖团队的卡资源分配正在向预训练和后训练 1:1 的方向收敛
| 阶段 | 过去(Chat 时代) | 现在(Agent 时代) |
|---|---|---|
| 预训练 | 60% | 33% |
| 研究 | 30% | 33% |
| 后训练 | 10% | 33% |
- 研究效率因为智能体框架编排,已经从周级压缩到小时级
她直接说:过去自己以为做的工作已经足够有创造力,不会被 Skill 化和工作流化,但现在发现它竟然也能。
这种自我冲击在一个亲手训模型的研究者身上发生,比任何外部预测都更说明问题。
她还提到一个判断:预训练模型从 1T 参数水平往上 scaling 是必经之路,但这条路上要押的是参数量,还是别的维度(比如多模态融合),是当下立刻需要决策的问题。这种判断会决定半年以后谁更领先。
罗福莉还谈到了一个很有意思的组织变化:做后训练现在的一个重要范式是需要多样性,让做预训练的人转去做后训练,能形成很好的补充。这种组织级的人员流动,意味着大模型公司内部的部门壁垒在被重新定义。
她说接下来两三个月会非常精彩:大家正在重新分配卡、重组团队、调整研究方向,谁能更快适应新范式,谁就有可能在下半年拿到领先。
她还提到一个观察很值得想一想,研究者本身的工作也在被技能化。过去研究员引以为傲的是设计实验、分析结果、写论文这种创造性工作,但现在用智能体框架编排,整个研究循环可以被一段一段地外包给系统。这种自我冲击是从一个一线研究者口中说出来的,不是外部观察者的预测。这条信号比任何宏观判断都更具说服力。
→ 阅读原文:138. 对罗福莉 3.5 小时访谈:AI 范式已然巨变
阮一峰《科技爱好者周刊》:第二次 API 开放浪潮

最后想聊一下阮一峰的《科技爱好者周刊》本周这期。整期周刊汇总了很多本周值得一看的科技内容,推荐大家直接读原文。这里我只展开其中一段我印象最深的观察,第二次 API 开放浪潮。
阮一峰的判断是:
| 浪潮 | 时间 | 驱动力 | 服务对象 |
|---|---|---|---|
| 第一次 | 2011 年 | 云服务兴起,平台希望第三方扩展 | 应用程序 |
| 第二次 | 2025 年下半年 | 大模型必须调用其他平台 | AI 代表用户行事 |
第一次浪潮里,Facebook、Twitter、GitHub 都开放了 API,但后来因为商业模式跑不通,平台陆续关上了门。
本周正在发生的第二次浪潮则有本质差别:
- 开放范围:这次被卷进来的不只云服务,还有外卖、电商、银行、餐馆预订
- 调用方式:不用手动写代码,自然语言由大模型翻译后调用
- 使用目的:API 这次服务的对象从应用程序切换到了 AI,也就是代表用户行事的智能体
腾讯也意识到了这一点,所以才会在 OpenClaw 爆红后用最快速度开放微信接口,让智能体可以向微信发消息。强如腾讯都怕在智能体世界里没有自己的位置,其他平台都在抢着通过 MCP 开放自家的接口。
→ 阅读原文:科技爱好者周刊(第 394 期):第二次 API 开放浪潮
四篇访谈合起来看到的图景
- OpenAI 在准备从模型公司转型为智能体基础设施公司
- 罗福莉 在告诉国内同行卡的分配要变
- 阮一峰 在告诉所有平台 API 开放是新的入场券
共同的底色是:2026 年的 AI 行业正在经历一次结构重组,基础设施层、模型层、应用层都在被重新定义。这种重组的速度比过去任何一次技术换代都要快,留给每家公司适应的时间窗口都很短。
如果把这周这 20 篇内容做一次归纳,最值得记下的是一种新的分工:
- 模型公司:把通用能力推到能可靠完成长程任务的水平
- 基建公司:为智能体重新设计计算和路由层
- 平台公司:开放接口让 AI 能代表用户行事
- 开发者:用 Skill 和 Harness 把这一切组装成具体的工作流
每一层都在变,但每一层该做什么反而比以前更清晰了。
七、本周关键判断与下周展望
整体节奏回顾
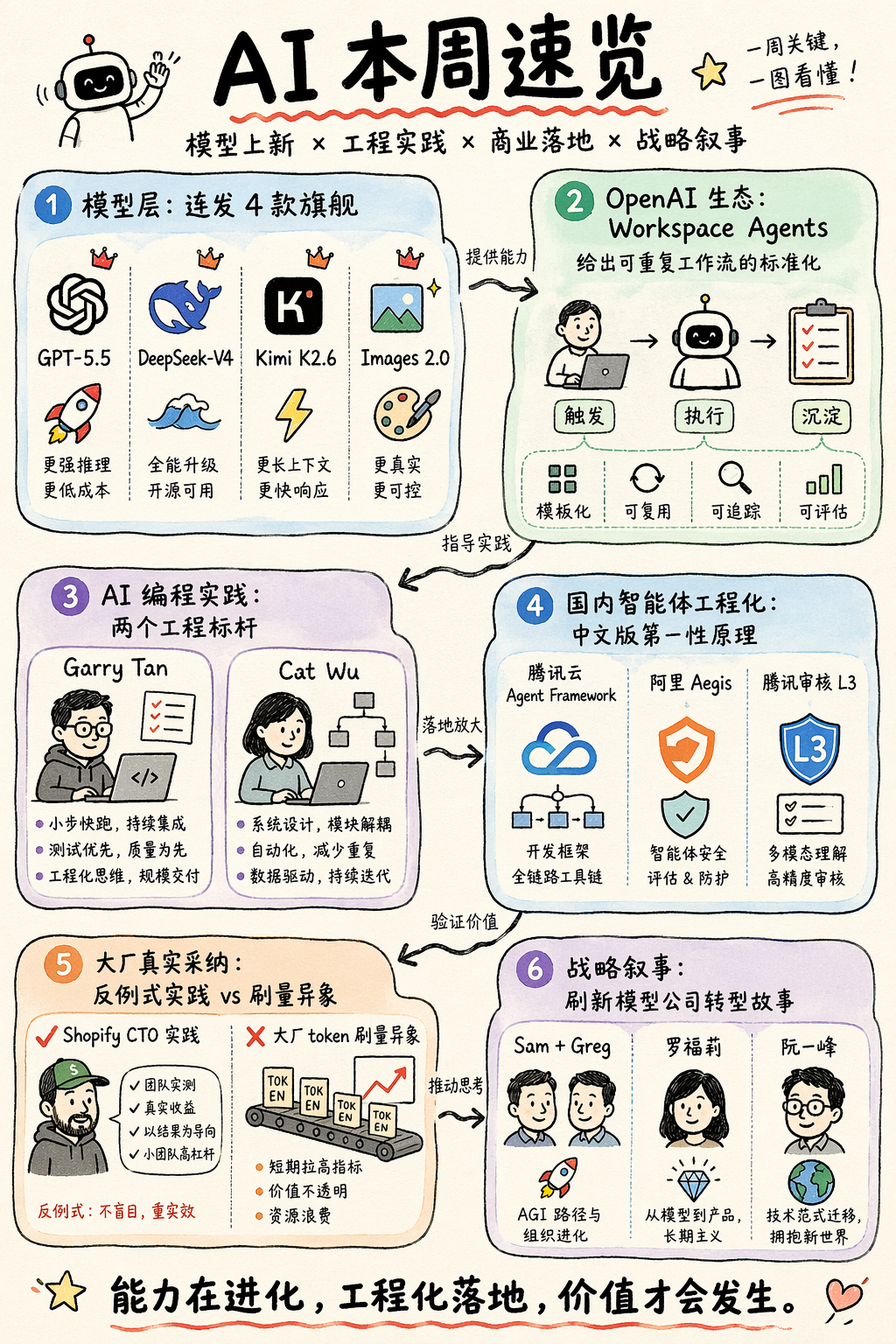
| 板块 | 关键事件 |
|---|---|
| 模型层 | 连发 4 款旗舰:GPT-5.5、DeepSeek-V4、Kimi K2.6、Images 2.0 |
| OpenAI 生态 | Workspace Agents 给出可重复工作流的标准化 |
| AI 编程实践 | Garry Tan 和 Cat Wu 给出工程纪律的两个标杆 |
| 国内智能体工程化 | 腾讯云、阿里 Aegis、腾讯审核 L3 同周给出中文版第一性原理 |
| 大厂真实采纳 | Shopify CTO 反例式实践 vs 大厂 token 刷量异象 |
| 战略叙事 | Sam+Greg、罗福莉、阮一峰 分别从不同角度刷新模型公司转型故事 |
个人推荐
最值得花时间深读:Shopify CTO 在 Latent Space 那场访谈。它把过去半年的所有抽象判断都落到了一个具体公司的具体动作上,让你看到 20 年老公司是怎么在 AI 时代重新定义工作方式的。
最值得跟着实践的方向:Garry Tan 的 GStack 思路加上 Cat Wu 的 100% 自动化建议。这两件事放在一起,是任何一个想用 AI 改变自己工作方式的人都可以立刻开始的。
下周值得关注什么
- GPT-5.5 在更多真实场景里的反馈,尤其是它在长程任务上的稳定性
- DeepSeek-V4 发布后的市场反馈
- 国内智能体工程化继续深入,特别是其他大厂可能跟进给出自己的版本
- BestBlogs 的后续开发:个性化推荐、早报图文体验、移动端、新增话题功能这几块都会陆续推进,进展会同步在周刊里
完整周刊
本期 20 篇精选完整列表:https://www.bestblogs.dev/newsletter/issue92
🎧 同步播客:EP37 · BestBlogs 周刊第 92 期 · 模型周(在小宇宙搜索 BestBlogs 周刊)
PS:欢迎大家添加 Gino 的微信(ID:ginobot)加入 BestBlogs 交流群,一起讨论 AI 相关话题。
