原文:Humans and Agents in Software Engineering Loops · Martin Fowler
引言:Vibe Coding 浪潮席卷开发者社区之后,一个核心争论始终没有平息:人类到底该在 AI 编程中扮演什么角色——放手让 Agent 全权处理,还是紧盯每一行生成的代码? Martin Fowler 在这篇文章中给出了一个更精准的框架。他把软件开发拆解为两个循环:Why 循环关注我们为什么要做这件事,How 循环关注具体怎么做。在此基础上,他提出了人类参与的三种模式:人在环外(Out of the Loop)、人在环中(In the Loop)和人在环上(On the Loop)。 其中最有启发性的是人在环上这种模式,其核心思路是:与其逐行审查 Agent 的代码产出,不如去构建和优化指导 Agent 工作的驾驭体系(Harness Engineering),包括 Spec 定义、质量检查和工作流指引。当产出不符合预期时,不是直接去修改产出内容,而是去改进产出它的那套机制。 这个视角让我想到在使用 Claude Code 开发出现 Bug 时,经常纠结是手动修复生成的问题代码,还是花时间去完善提示词 和 CLAUDE.md 等规则文件?Martin Fowler 的建议是后者,因为这才是可持续的路径,而且最终能演化成一个自我持续改进的飞轮。 推荐所有正在探索 AI 编程工作流的开发者阅读。
人类是否应该退出软件开发流程,全面拥抱 Vibe Coding?还是说我们必须始终参与其中,逐行审查代码?我认为答案在于始终聚焦目标,把想法变成可用的成果。人类最合适的位置,不是撒手不管让 Agent 自由发挥,也不是事无巨细地审查它们的产出,而是去构建和管理整个工作循环。我把这种模式叫做人在环上(On the Loop)。
两个循环
作为软件创造者,我们通过把想法变成可运行的软件来实现目标,并在过程中不断学习、迭代和优化。这就是 Why 循环。在 AI 真正觉醒之前,人类会一直主导这个循环,因为我们才是那个想要成果的主体。
实际构建软件的过程则是 How 循环。How 循环涉及创建、选择和使用各种中间产物,包括代码、测试、工具、基础设施,也可能包括技术设计文档和 ADR(Architecture Decision Record)之类的文档。我们习惯把其中很多东西当作交付物,但中间产物终究只是达成目标的手段。
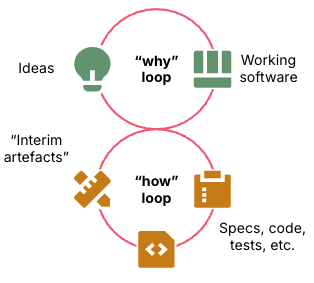
图 1:Why 循环围绕想法和软件进行迭代,How 循环围绕构建软件的中间产物进行迭代。上层 Why 循环连接着下层 How 循环,Why 循环在想法与可运行软件之间迭代,How 循环在规约说明、代码、测试等中间产物之间迭代。
实际上 How 循环内部包含多个层级。最外层负责按照 Why 循环的要求交付完整的可运行软件,最内层负责生成和测试代码。中间的层级把上层的大任务拆解成更小的任务交给下层执行,再验证结果。
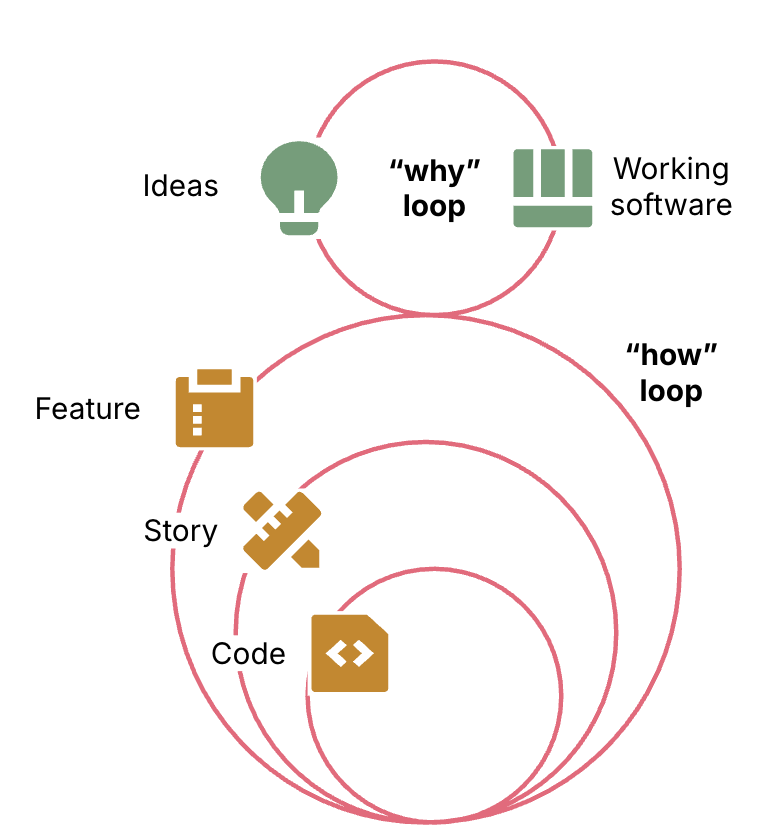
图 2:How 循环内部有多个层级的子循环,处理越来越小的实现单元。外层循环围绕 Feature 迭代,中间层围绕 Story 迭代,内层围绕代码迭代。
这些循环可能遵循设计评审、测试阶段等实践,也可能采用微服务或 CUPID 之类的架构模式来构建系统。和循环中产出的这些中间产物一样,这些实践和模式本身也只是实现目标的手段。
那么问题来了:我们是否需要关心实现目标的手段?能不能干脆让 LLM 按自己的方式运行整个 How 循环?
人在环外(Humans Outside the Loop)
已经有很多人体验过这种快感:人类只管 Why 循环,How 循环完全交给 Agent。这就是通常意义上的 Vibe Coding。某些对 SDD(Spec Driven Development,规约驱动开发)的理解也大致如此,人类花力气描述想要的结果,但不去规定 LLM 该怎么实现。
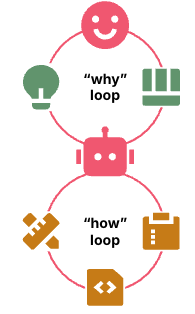
图 3:人类运行 Why 循环,Agent 运行 How 循环。上层 Why 循环由人类主导,在想法与可运行软件之间迭代;下层 How 循环由 Agent 主导,在代码等中间产物之间迭代。
人类远离 How 循环的吸引力在于,Why 循环才是我们真正在意的东西。软件开发是个混乱的领域,难免陷入过度工程化的流程和无休止的技术债中。而每一代新的 LLM 模型都在更好地把用户的 prompt 转化为可运行的软件。如果你对产出不满意,告诉 LLM,它会给你下一个迭代。
如果 LLM 能自行编写和修改代码,我们还需要关心代码是否干净吗?只要 LLM 能看懂,变量名是否清晰地表达了用途又有什么关系?也许我们甚至不需要在意软件是用什么语言写的。
我们真正关心的是外部质量,而不是内部质量本身。外部质量是用户或其他利益相关者实际体验到的东西。功能质量是底线,系统必须正确运行。对于生产环境的软件,我们还关心非功能性的运维质量:系统不能崩溃,要运行得足够快,不能把机密数据发到社交媒体上,不能产生巨额云服务账单,在很多行业还要通过合规审计。
内部质量之所以重要,是因为它会影响外部结果。当人类程序员在代码库中穿梭、添加功能、修复 Bug 时,干净的代码库能让他们更快、更可靠地完成工作。但 LLM 不在乎开发者体验,对吧?
理论上,我们的 LLM Agent 可以硬挤出一个极度复杂的意大利面条式代码库,靠跑一堆临时的 Shell 命令来测试和修复,最终也能产出一个正确、合规、高性能的系统。我们只需要让一群 Agent 像 Ralph Wiggum 那样瞎忙活,跑在漂浮于沸腾海洋上的数据中心里,总有一天能搞定。
但在现实中,设计清晰、结构良好的代码库相比混乱的代码库有实实在在的外部价值。LLM 能更快地理解和修改代码,就意味着更高的效率和更少的死循环。我们确实关心构建系统所花的时间和成本。
人在环中(Humans in the Loop)
有些开发者认为,维护内部质量的唯一方式就是深度参与 How 循环的最底层。很多时候 Agent 在某段有问题的代码上反复打转,人类开发者却能在几秒内理解并修复。在不少场景下,人类的经验和判断力仍然明显优于 LLM。
图 4:人类同时运行 Why 循环和 How 循环。这是一个合并的循环,人类在上方,Agent 在下方,循环在想法、代码和测试等中间产物、可运行软件之间迭代。
当人们说人在环中(Human in the Loop)时,通常指的是人类在代码生成的最内层循环中充当把关者,比如手动检查 LLM 生成的每一行代码。
但过度深入参与会带来一个问题:人类会变成瓶颈。Agent 生成代码的速度远快于人类手动审查的速度。关于 AI 对开发者生产力影响的报告结论不一,部分原因可能在于,人类花在编写规约说明和审查代码上的时间,反而比 LLM 帮我们节省下来的编码时间还多。
我们需要采用经典的左移(Shift Left)思维。过去我们先写完所有代码,再交给 QA 团队测试,然后试着修够多的 Bug 来发布一个版本。后来我们发现,让开发者在编码过程中自己编写和运行测试,能立即发现和修复问题,整个流程因此变得更快、更可靠。
对人类有效的方法,对 Agent 同样适用。当 Agent 能自行评估代码质量而不依赖我们手动检查时,它们的产出会更好。我们需要做的是清晰告诉它们期望什么,并给出实现目标的最佳指导。
人在环上(Humans on the Loop)
与其亲自检查 Agent 的产出,不如让它们更擅长产出。那套控制 How 循环各层级的规约说明、质量检查和工作流指引,就是 Agent 的驾驭体系(Harness)。构建和维护这套体系的实践叫做驾驭工程(Harness Engineering),也就是人类在环上工作的核心方式。
图 5:人类定义 How 循环,Agent 执行 How 循环。上层 Why 循环连接着下层 How 循环,连接点是人类。Agent 位于下层 How 循环的底部,在规约说明和代码等中间产物之间迭代。
类似人在环上的概念也被称为中间循环(Middle Loop),The Future of Software Development Retreat 研讨会的参与者就使用过这个说法。中间循环指的是把人类的注意力从编码层提升到更高层级的循环。
人在环中和人在环上最大的差别,体现在我们对 Agent 产出不满意时会怎么做。人在环中的做法是直接修复产出物,要么亲手改,要么告诉 Agent 做出具体的修正。人在环上的做法则是调整产出这个结果的驾驭体系,让它下次能产出我们想要的东西。
我们通过持续改进驾驭体系来持续提升产出质量。在此基础上,我们还可以更进一步。
Agent 飞轮(The Agentic Flywheel)
下一个层级是让人类指导 Agent 来管理和改进驾驭体系,而不是亲手操作。
图 6:人类引导 Agent 来构建和改进 How 循环。上层 Why 循环通过人类和 Agent 共同连接到下层 How 循环。Why 循环在想法与可运行软件之间迭代,How 循环在规约说明等中间产物之间迭代。
构建飞轮的方式是为 Agent 提供评估循环表现所需的信息。一个好的起点是驾驭体系中已有的测试和评估。当我们输入更丰富的信号时,飞轮会变得更强大。比如添加衡量性能和验证故障场景的流水线阶段,输入生产环境的运维数据、用户旅程日志和商业结果,来拓宽 Agent 分析的范围和深度。
在工作流的每个步骤,让 Agent 审查结果并推荐驾驭体系的改进方案,推荐范围涵盖所有上游环节可能带来的优化。到这一步,我们就拥有了一个能为自身生成改进建议的驾驭体系。
起初我们在交互式对话中考量这些建议,提示 Agent 执行具体的变更。也可以让 Agent 把建议写入产品 Backlog,这样我们就能排优先级,安排 Agent 在自动化流程中去领取、应用和测试这些改进。
随着信心的积累,Agent 可以为自己的建议打分,涵盖风险、成本和收益。我们可以设定规则,让达到一定分数的建议自动批准并应用。
发展到某个阶段,这看起来可能很像人在环外,也就是老派的 Vibe Coding。我猜对于那些频繁执行的标准化工作来说确实如此,因为改进循环最终会触及收益递减的边界。但通过驾驭工程,我们得到的不只是一次性的凑合方案,而是持续自我改进的健壮系统,甚至可能是反脆弱的系统。