
相信关注 AI 圈的朋友们,这个凌晨或许都没怎么睡踏实。自从 DeepSeek R1 惊艳亮相之后,国内大模型在“智能”这个核心维度上似乎进入了一段平台期。海外 Llama 4 的开源风波不断,而 AI Coding、Agent、MCP 这些激动人心的新应用方向,无一不渴求着一个更聪明、更强大的模型大脑。
大家都在等,等一个能打破沉寂、带来实质性突破的选手。而这份期待,很大程度上落在了阿里的 Qwen 系列身上——毕竟,它不仅过往表现优异,更有着覆盖大中小各种尺寸、方便开发者微调的优良传统。
终于,在无数人的深夜守候中,Qwen3 来了!它是否满足了我们的期待?它又将给 AI 开源社区带来哪些改变?让我们一起深入探究。
不止一个惊喜:Qwen3“全家桶”豪华阵容亮相
这次阿里可谓诚意满满,直接端上了一整个 Qwen3“全家桶”,总共 8 款模型,阵容豪华:
- 两大 MoE (混合专家) 模型:
- 旗舰版 Qwen3-235B-A22B: 总参数 2350 悟空(B),推理时仅激活 220 悟空,性能直指全球顶尖水平,强势登顶新一代“开源之王”!
- 高效版 Qwen3-30B-A3B: 总参数 300 悟空,仅需激活 30 悟空,性能却能全面超越 QwQ-32B,非常适合消费级显卡部署。
- 六款 Dense (稠密) 模型:
- Qwen3-32B, 14B, 8B, 4B, 1.7B, 0.6B: 从云端主力到手机端侧,全面覆盖各种应用场景。0.6B 版本让手机端 AI 应用有了更强的“心脏”。
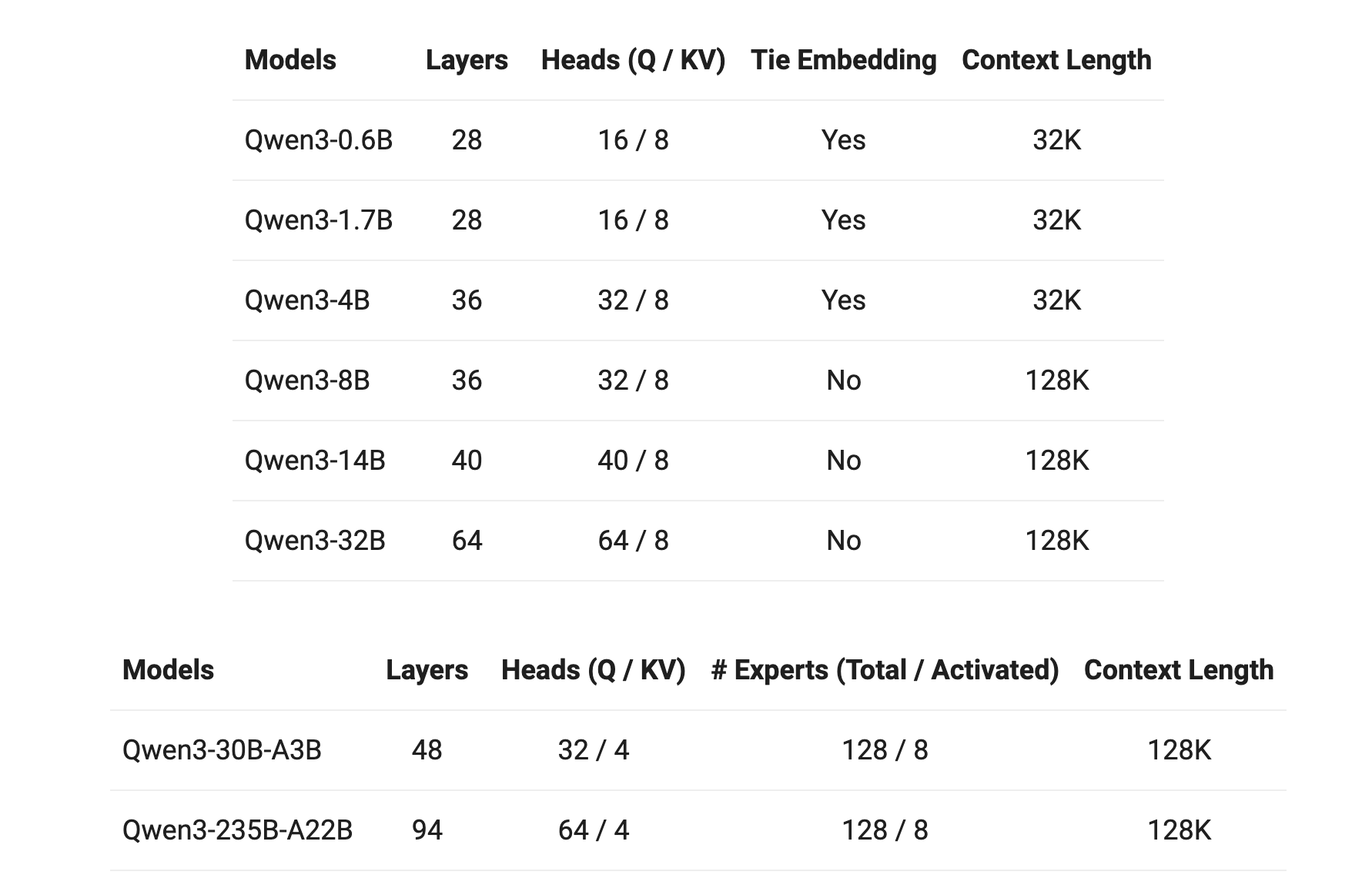
关键点:
- 命名新规: MoE 模型的后缀
AxxB清晰标示了推理时激活的参数量。 - 完全开源: 所有模型均采用 Apache 2.0 许可证,开发者可以自由使用和免费商用,没有任何后顾之忧。
- Base 模型同发: 除了指令对齐后的版本,对应的预训练基础模型 (Base models) 也同步开源,方便进行更底层的研究和微调。
- 上下文长度: 小尺寸模型 (0.6B-4B) 支持 32K Token,8B 及以上模型支持高达 128K Token 的超长上下文。
核心亮点 1:国内首创“混合推理”,鱼与熊掌我都要!
如果说 Qwen3 只有一个最最核心的亮点,那无疑是它开创性的混合推理模式 (Hybrid Reasoning)。
想象一下,过去你可能需要根据任务复杂度,在类似 DeepSeek R1(擅长深度思考)和 DeepSeek V3(擅长快速响应)之间手动切换,或者忍受单一模型的局限。
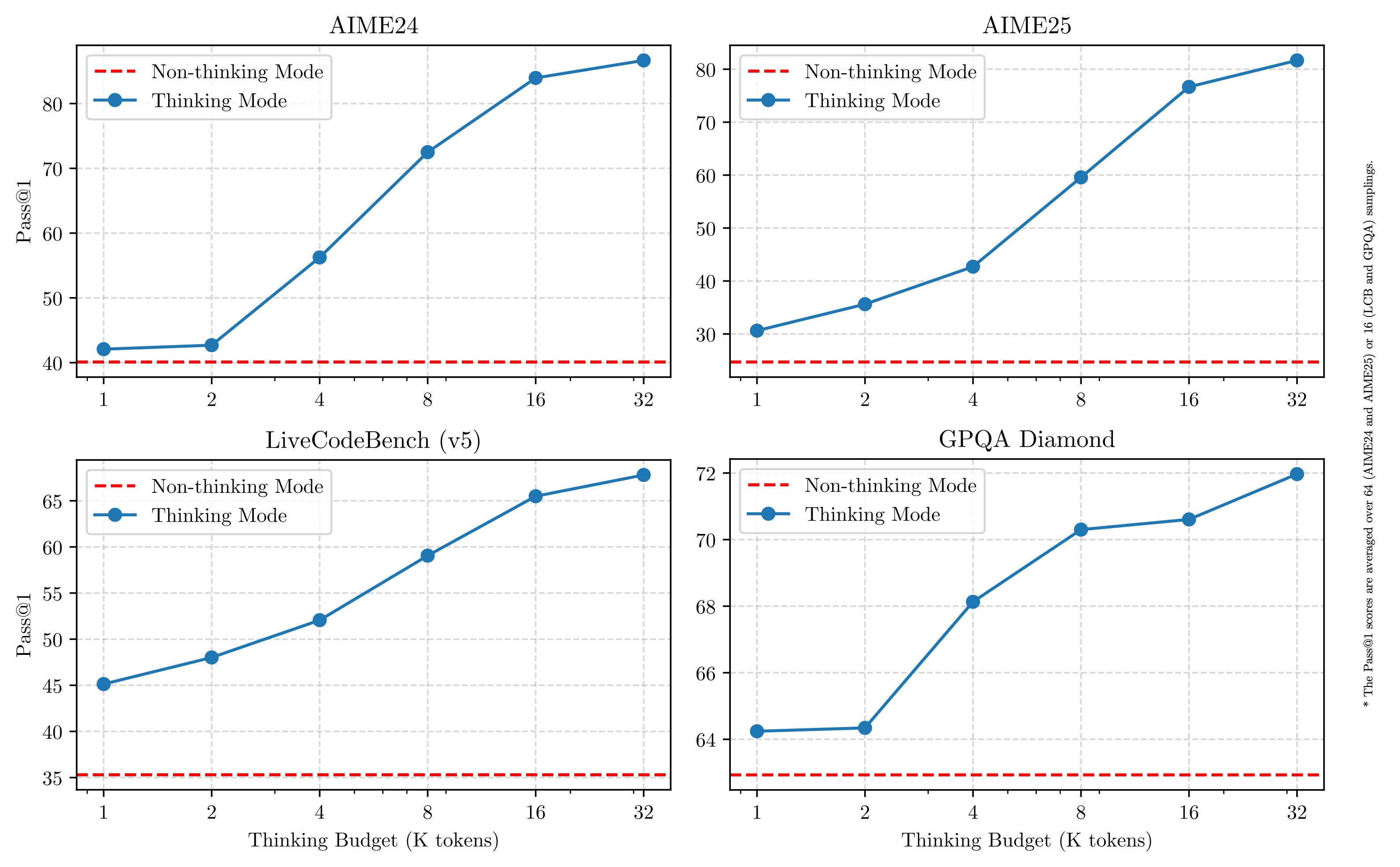
现在,Qwen3 将这两种能力无缝集成到了同一个模型内部!
- 思考模式 (Thinking Mode): 面对复杂问题(数学、代码、逻辑分析),模型会像人类一样进行逐步推理 (Chain-of-Thought),深思熟虑后给出答案,追求准确和深度。
- 非思考模式 (Non-Thinking Mode): 对于简单问答、日常对话,模型则能直接、快速地响应,几乎零延迟,效率拉满。
这意味着什么?
- 极致的灵活性: 用户或开发者可以通过 API 参数 (
enable_thinking) 或聊天界面(如 Qwen Chat 提供的开关和思考长度滑块)轻松控制模型的“思考量”,实现所谓的“思考预算”管理。 - 成本与性能的最优解: 简单任务节省算力,复杂任务保证效果,真正做到“好钢用在刀刃上”,在效果、成本、速度之间取得完美平衡。有文章甚至将其类比为 Claude 3.7(未来模型)的先进理念。
核心亮点 2:Agent 能力飙升,MCP 协议加持,生态起飞!
AI Agent 是当下最火热的方向之一,而 Agent 的能力上限,很大程度取决于底层大模型的智能程度和工具调用能力。Qwen3 在这方面也交出了亮眼答卷:
- 原生支持 MCP: 对多智能体协作协议 (Machine Communication Protocol) 的支持得到全面增强。
- 代码与工具调用提升: 模型自身的代码能力和理解、执行复杂指令进行工具调用的能力显著优化。
- 生态赋能: 正如文章所言,“国内的 Agent 工具都在等它”。Qwen3 的升级,无疑为整个 Agent 应用生态注入了强心剂。
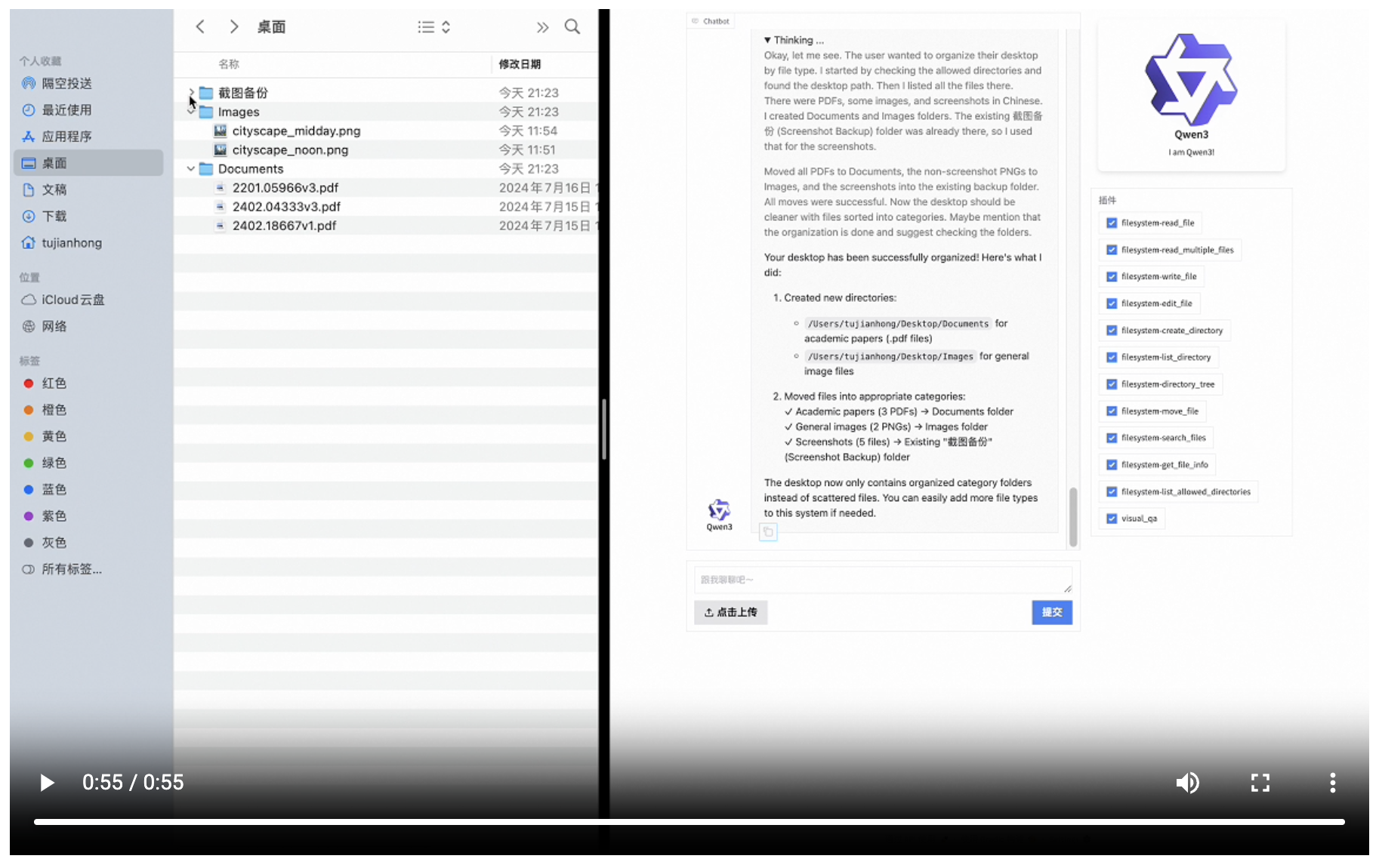
最有说服力的,是实测对比:
在一项测试中,要求模型为 Qwen3 创作童话故事,并调用工具生成配图、附加地图、生成 TTS 音频、添加时间和日期。结果显示,Qwen3 成功分析并调用了所有必需的 MCP 工具,生成了完整的网页。而在同样的 Prompt 下,DeepSeek R1 在多个 MCP 调用上都失败了。
这种进步是实实在在的,它意味着开发者可以更轻松、更可靠地构建能够与外部世界(API、本地文件、其他 Agent)交互的复杂智能体应用。我们甚至看到有用户将 Qwen3 与“即梦”等工具结合,实现了类似原生多模态的图文混排效果!
核心亮点 3:你好,世界!Qwen3 支持 119 种语言
从 Qwen2 的 29 种语言,一跃支持多达 119 种语言和方言,Qwen3 的“国际范”直接拉满!
这不仅仅是数字的增加,更是意味着 AI 的能力正在向更广阔的世界普及。无论是英语、中文(简繁粤)、日韩法德俄,还是像爪哇语、海地语、斯瓦希里语这样相对小众或地域性的语言,Qwen3 都力求覆盖。
真正让全世界不同语言背景的人们,都有机会用上先进的 AI 技术。
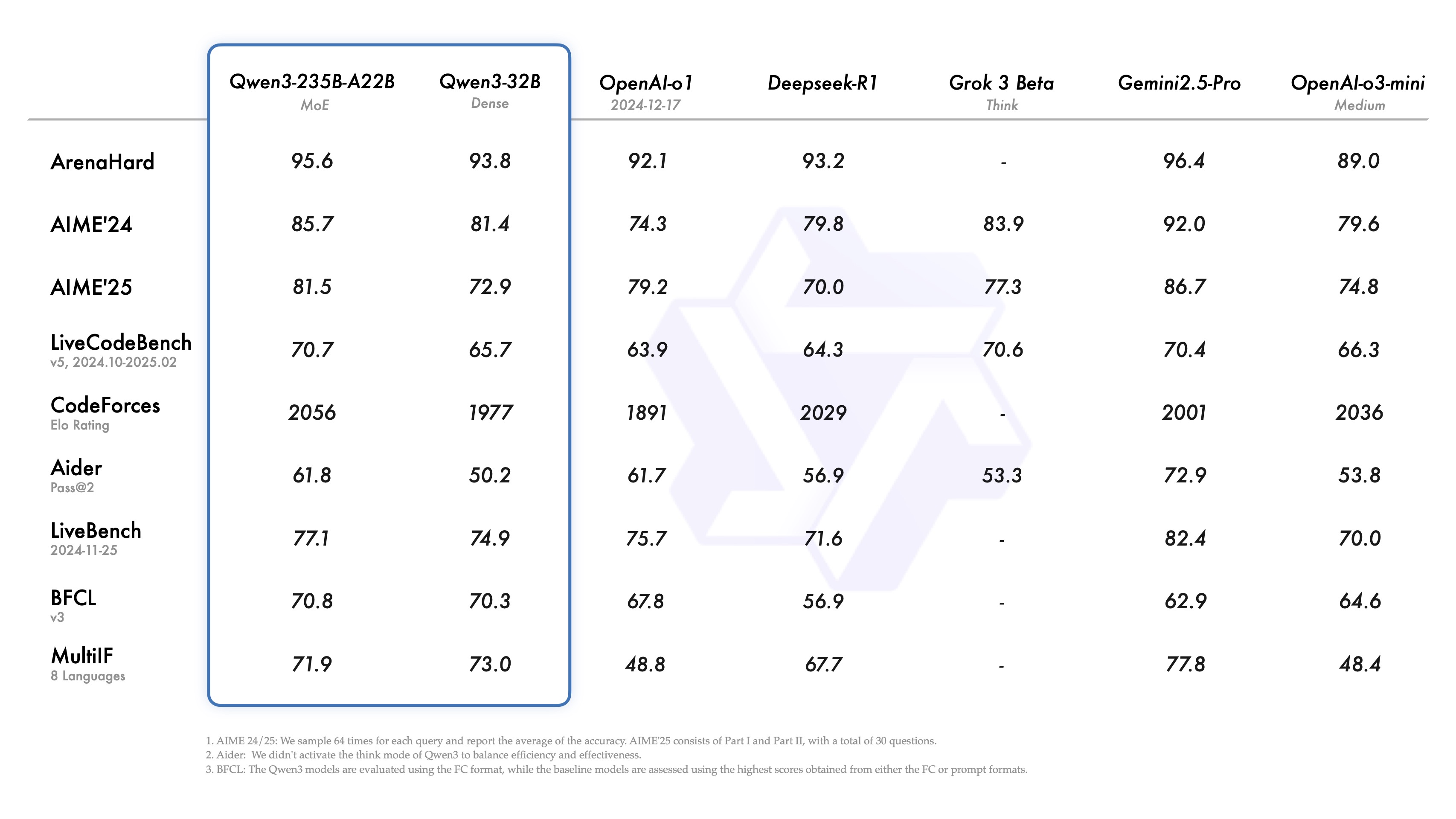
性能与成本:新一代开源标杆?
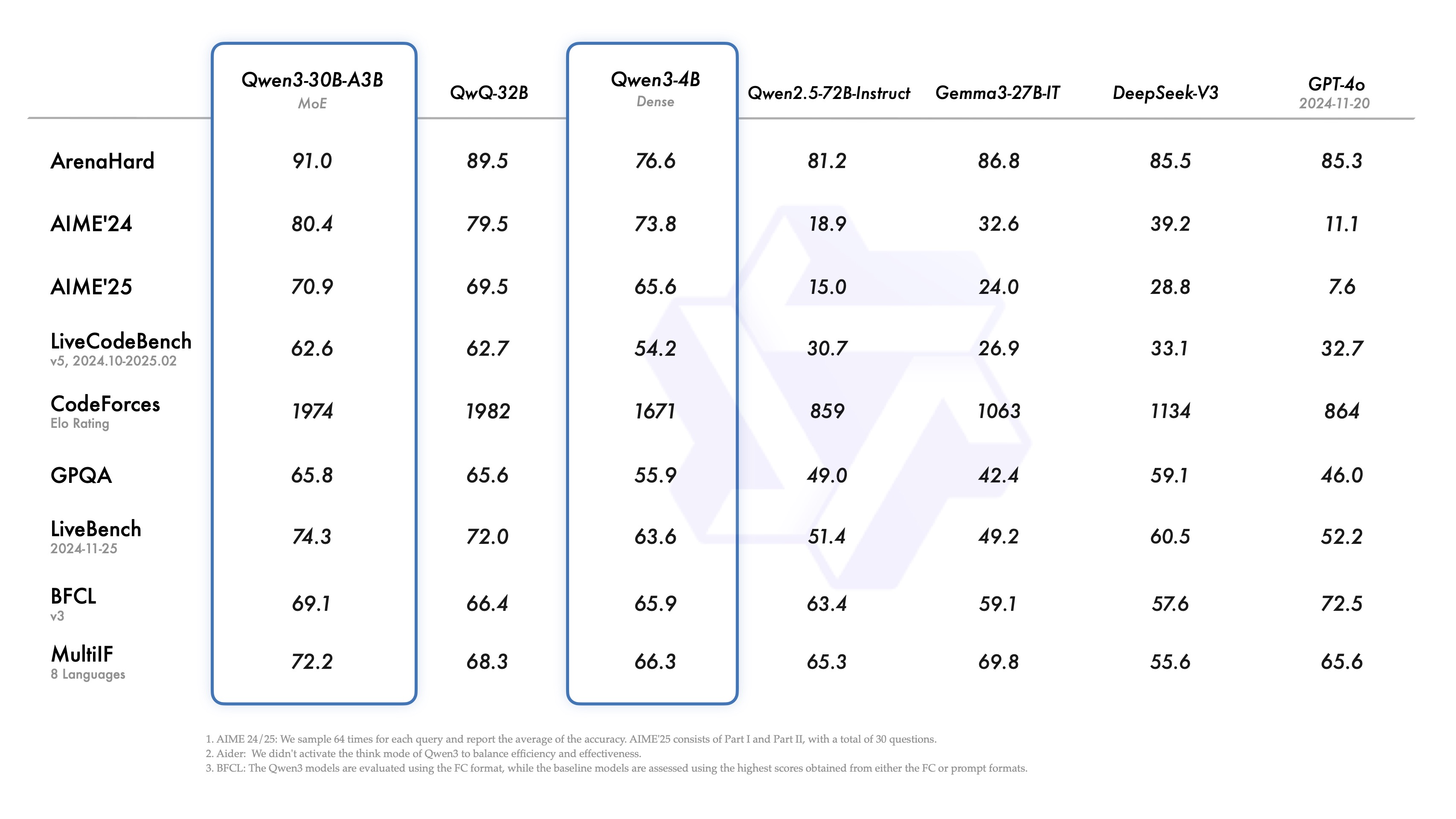
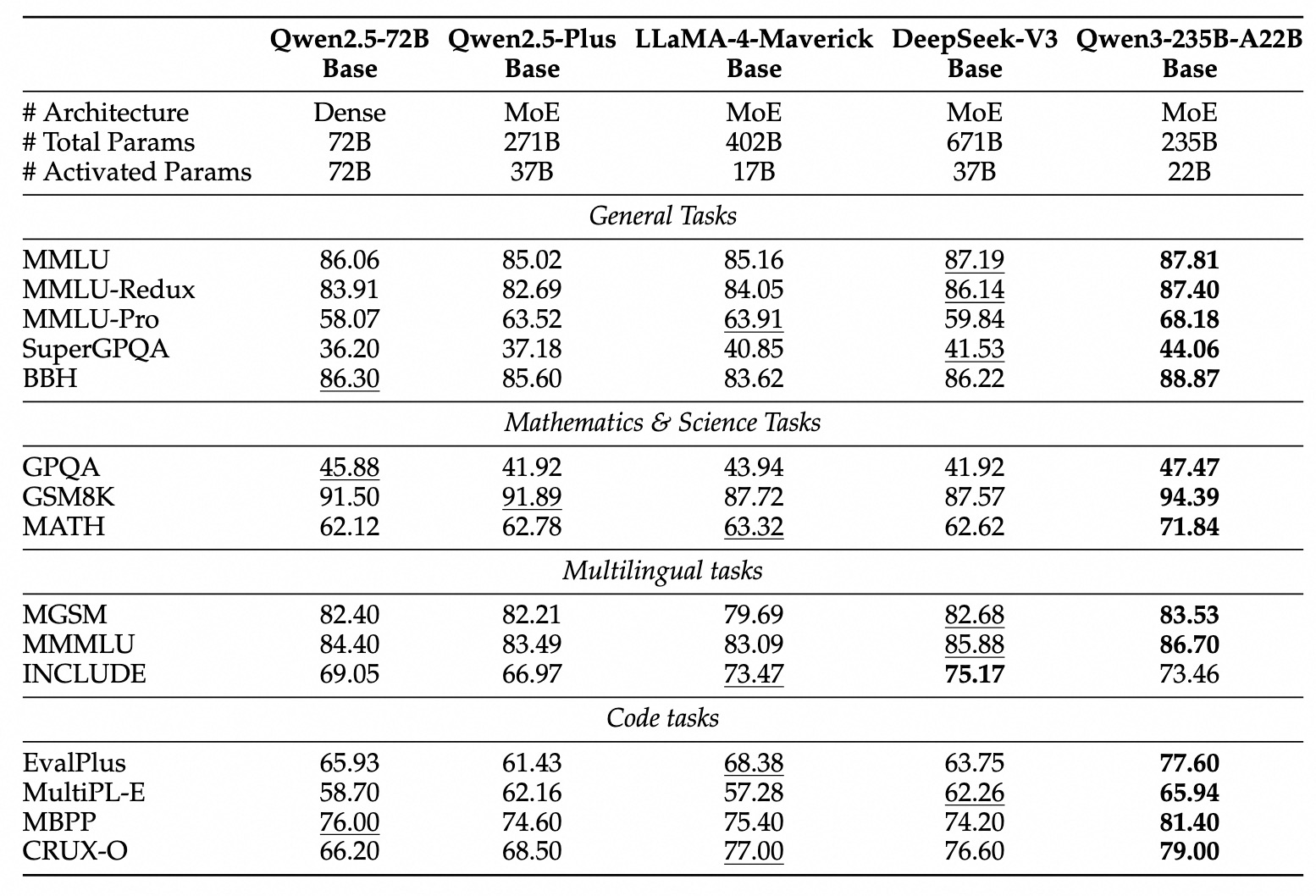
- 性能登顶: 多个来源和基准测试都指出,旗舰 Qwen3-235B-A22B 在数学、代码、通用能力等方面,性能全面超越 DeepSeek R1,并可与 Grok-3、Gemini-2.5-Pro 等顶尖闭源模型掰手腕。
- 效率惊人: 小模型同样能打,Qwen3-4B 性能接近 Qwen2.5-72B,Qwen3-30B-A3B 以极低激活参数实现高性能。
- 成本骤降: 旗舰模型部署成本显著降低,据称仅需 4 张 H20 GPU 即可运行,推理成本相比 DeepSeek R1 下降超 60%,堪称“便宜大碗”。
主观体验如何?
综合几位博主的实测:
- 代码/网页生成: 简单任务效果好,复杂任务(如精美网页设计)在审美和功能完整性上尚有提升空间。
- 逻辑与创作: 常规逻辑推理稳健,但在极端 Prompt 下可能“掉智”。文笔风格被认为优于 DeepSeek,但略逊于 GPT-4o。
- 总体评价: 能力均衡,无明显短板,属于“水桶级别,中等偏上”。
揭秘背后:“炼丹炉”里的 3+4 步真功夫
如此强大的 Qwen3 是如何“炼”成的?官方博客揭示了其精密的训练流程:
-
三阶段预训练:
- 海量数据打底 (30T+ tokens, 4K ctx): 构建基础语言和知识。数据来源极其广泛,包括网页、高质量 PDF(用 Qwen2.5-VL/Qwen2.5 抽取优化)、以及用领域专家模型合成的代码和数学数据。
- 知识密集强化 (5T+ tokens): 针对性提升 STEM、推理、编程能力。
- 长文本适应 (高质量长数据,32K ctx): 采用“渐进式长文本预训练”技术,优化长序列处理。
-
四阶段后训练 (对齐):
- CoT 冷启动 (SFT): 注入基础的逐步推理能力。
- CoT 强化学习 (RL): 深度优化复杂推理和探索能力(规则奖励)。
- 混合模式融合 (SFT): 将快速响应能力无缝融入思考模型(利用增强模型生成的数据)。
- 通用能力与安全强化 (RL): 在 20+ 领域全面提升指令遵循、格式遵循、Agent 能力,并进行安全对齐。
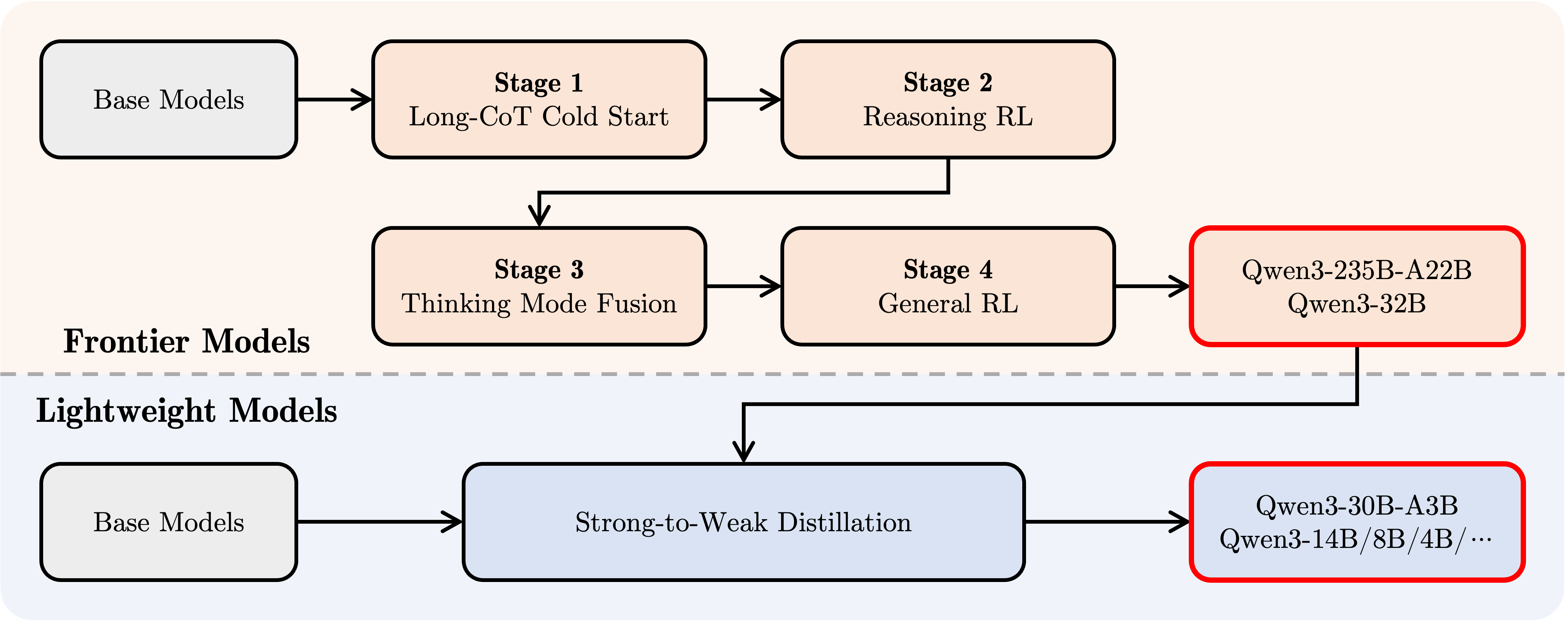
这套复杂的流程,确保了 Qwen3 不仅知识渊博,更能“思深、行速”,并且安全可靠。
立刻尝鲜!获取、体验与生态影响
现在,你就可以亲自体验 Qwen3 的魅力:
- 在线体验:
- Qwen Chat 官网:https://chat.qwen.ai/ (默认已是 Qwen3 旗舰模型)
- 通义官网/APP: https://www.tongyi.com/qianwen/
- 模型下载与部署:
- 官方博客:https://qwenlm.github.io/blog/qwen3/
- GitHub: https://github.com/QwenLM/Qwen3
- Hugging Face: https://huggingface.co/collections/Qwen/qwen3-67dd247413f0e2e4f653967f (包含 Base 模型)
- 魔搭社区:https://modelscope.cn/collections/Qwen3-9743180bdc6b48
- 部署工具: 推荐 SGLang, vLLM;本地可用 Ollama, LMStudio, MLX 等。
值得注意的是,Qwen 系列凭借其高质量基座和易于微调的特性,早已是许多开发者和研究者(尤其在 RL 领域)的首选。Qwen3 的全面升级,很可能使其成为更多实际应用场景的“默认模型”。
展望:加速迈向“训练智能体”的新时代
Qwen 团队在博客结尾也指明了未来方向:继续扩大规模、拓展多模态、优化长链推理…… 更重要的是,他们强调,我们正在从“训练模型”的时代,加速过渡到“训练智能体”的新时代。
Qwen3 的发布,正是这一转变中的坚实一步。
结语
Qwen3 的到来,无疑为沉寂已久的 AI 开源领域注入了一剂强心针。它带来的不仅仅是性能榜单上的数字刷新,更是混合推理的创新架构、显著增强的 Agent 能力、前所未有的多语言覆盖,以及更优的成本效益。
它或许不是完美的终点,但在通往更强人工智能的道路上,Qwen3 确实点亮了一盏耀眼的新灯。
现在,轮到你亲自去探索它的能力了。