《智能体设计模式》中文翻译计划启动
正如《设计模式》曾是软件工程的圣经,这本由谷歌资深工程主管免费分享的《智能体设计模式》,正为火热的 AI 智能体领域带来首套系统性的设计原则与最佳实践。
本书由 Antonio Gulli 撰写、谷歌 Cloud AI 副总裁 Saurabh Tiwary 作序、高盛 CIO Marco Argenti 鼎力推荐,系统性地提炼出 21 个核心智能体设计模式,涵盖从提示链、工具使用到多智能体协作、自我修正等关键技术。
接下来的一段时间,我将和几位小伙伴一起通过「AI 初次翻译 → AI 交叉评审 → 人工评审 → 人工交叉评审」的方式来翻译这本书,所有翻译内容将会持续更新到开源项目:github.com/ginobefun/agentic-design-patterns-cn
已翻译章节:
- 00 -《智能体设计模式》前言部分
- 01 -《智能体设计模式》第一章:提示链模式
- 02 -《智能体设计模式》第二章:路由模式
- 03 -《智能体设计模式》第三章:并行模式
- 04 -《智能体设计模式》第四章:反思模式
- 05 -《智能体设计模式》第五章:工具使用模式
- 06 -《智能体设计模式》第六章:规划模式
- 07 -《智能体设计模式》第七章:智能体协作模式
多智能体协作模式精华概览
多智能体协作模式通过组织一组相互协作、各司其职的专长型智能体来突破单一智能体的能力边界。这种模式基于任务分解和专业化分工原则,将复杂的跨领域任务拆解为若干独立的子问题,并将每个子问题分配给拥有相应工具、数据权限或推理能力的智能体来处理。系统的效能不仅源于分工,更取决于智能体之间的通信机制和协调策略。这里为大家梳理几个核心要点:
1. 核心理念:从单一处理到协同分工
多智能体协作模式的核心在于建立「任务拆解 → 专业分工 → 协同工作 → 结果整合」的智能流程,让系统具备超越单一智能体能力的协同效应。智能体之间可以采取顺序、并行、层级、辩论等多种协作形式。
- 单一智能体的局限:在处理任务明确、范围清晰的问题时表现良好,但在面对需要多种专业知识、涉及多个独立阶段的复杂跨领域任务时往往力不从心。
- 协作模式的价值:通过多个专业智能体的分工协作,系统可以同时处理需要不同技能的子任务,单个智能体的故障不会导致整个系统瘫痪,整体表现往往超越任何单一智能体的能力上限。
2. 六种协作架构
多智能体系统支持多种通信和组织架构,从简单到复杂形成完整的谱系:
- 单智能体:独立运行,无需与其他智能体直接交互,适合可分解为独立子问题的场景。
- 网络化:去中心化的点对点交互,智能体直接共享信息、资源和任务,结构更具弹性。
- 监督者模式:专门的监督者智能体负责协调下级智能体,充当通信、任务分配和冲突解决的中心枢纽。
- 监督者作为工具:监督者提供资源、指导或分析来辅助其他智能体,而非直接指挥控制。
- 层级结构:多层组织结构,高层级监督者管理低层级监督者,底层是执行智能体,适合可拆分的复杂任务。
- 自定义架构:融合已有模型特点的混合方案或针对特定场景的全新设计,提供终极灵活性。
3. 六种协作形式
智能体之间的协作可以采取多种形式,每种都适用于不同的场景:
- 顺序交接:一个智能体完成任务后将输出交给下一个智能体,形成管道式工作流。
- 并行处理:多个智能体同时处理问题的不同部分,最后合并结果,提升整体效率。
- 辩论与共识:不同智能体通过讨论和评估各种方案,形成共识或得出更可靠的决策。
- 层级委派:管理型智能体根据执行型智能体的能力动态分配任务并汇总结果。
- 专家团队:由各领域专业智能体(如研究员、撰稿人、编辑)协同完成复杂任务。
- 评审者模式:一组智能体生成初始输出,另一组严格评估其质量、合规性和正确性,并据此改进。
4. 典型应用场景
多智能体协作模式在七大领域展现出核心价值:
- 复杂研究与分析:多个智能体协同完成研究项目,分工负责搜索、整理、分析和报告生成。
- 软件开发:由需求分析、开发、测试、文档等专职智能体协同开发和验证各个组件。
- 创意内容生成:市场调研、文案撰写、设计素材、社媒排期等专长智能体协同完成营销活动。
- 财务分析:不同智能体分别负责获取数据、分析情绪、技术分析和生成投资建议。
- 客户支持:一线智能体处理常见咨询,复杂问题按专业领域升级给相应的专家智能体。
- 供应链优化:代表供应链不同节点的智能体协作优化库存、物流和排期。
- 网络分析与故障修复:多个专职智能体协同进行问题排查、修复并提出最优处理建议。
5. 实现框架与特点
- CrewAI:创建智能体时定义角色、目标和背景故事,为每个智能体分配任务,通过
Crew组合智能体和任务列表,使用kickoff()启动顺序工作流。文中示例展示了研究员和写手协作完成博客创作的完整流程。 - Google ADK:提供丰富的智能体类型满足不同协作需求:使用
sub_agents参数建立层级关系;LoopAgent配合max_iterations实现循环执行;SequentialAgent通过output_key在会话状态中传递数据;ParallelAgent并发执行多个子智能体;AgentTool将智能体封装为工具供其他智能体调用。
6. 使用时机与权衡
当任务复杂度超出单个智能体的处理能力且可拆解为需要不同专业技能的子任务时,应当使用多智能体协作模式:
- 适用场景:任务需要多种专业知识;包含多个独立阶段或并行处理的子任务;能从不同智能体的相互验证中受益;单个智能体无法高效完成的复杂工作流。
- 权衡考量:增加了系统复杂度,需要精心设计通信协议和协调机制;需要权衡通信开销与性能提升;选择合适的架构模型(单智能体、网络化、监督者、层级等)取决于具体场景。
- 核心价值:通过分工协作实现协同效应,构建更具模块化、可扩展性和鲁棒性的系统,解决单个整体智能体无法应对的复杂问题。
以下为原书第七章多智能体协作模式的内容,译者:@Gino
单智能体在处理任务明确、范围清晰的问题时表现良好,但在面对更复杂的跨领域任务时往往力不从心。多智能体协作模式通过组织一组相互合作、各司其职的专长型智能体来克服这些限制。这种模式基于任务分解原则,将高层次目标拆解为若干独立的子问题,然后将每个子问题分配给拥有相应工具、数据权限或推理能力的智能体来处理,以发挥各自优势。
例如,一个复杂的研究问题可以这样拆分:由研究智能体负责信息检索、数据分析智能体负责统计处理、综合智能体负责生成最终报告。这类系统的效果不仅源于分工,更取决于智能体之间的通信机制。为此需要标准化的通信协议和共享机制,使智能体之间能够交换数据、委派子任务和协调行动,以确保最终结果的连贯一致。
这种分工协作架构具有多项优势,包括更强的模块化、可扩展性和鲁棒性。因为单个智能体的故障不一定会导致整个系统瘫痪。更重要的是,通过分工协作,多智能体系统能够发挥协同效应,其整体表现往往超越任何单个智能体的能力上限。
多智能体协作模式概览
多智能体协作模式是指设计由多个独立或半独立智能体组成的系统,它们之间协同工作以实现共同目标。每个智能体通常承担明确的角色,拥有与整体目标一致的目标,并可以使用不同的工具或知识库。其强大之处在于智能体之间的互动与协同,能够产生超越单体能力的协同效应。
协作可以有多种形式:
- 顺序交接: 一个智能体完成任务后将输出交给另一个智能体继续处理,形成管道式工作流(类似于规划模式,但涉及不同的智能体)。
- 并行处理: 多个智能体同时处理同一问题的不同部分,最后将各自的结果进行合并。
- 辩论与共识: 在多智能体协作中,来自不同视角和信息来源的智能体通过讨论和评估各种方案,最终形成共识或得出更加可靠的决策。
- 层级结构: 管理型智能体可以根据各个执行型智能体的工具权限或插件能力,动态分配任务并汇总结果。每个智能体也可以负责一组相关工具,而不是让单个智能体承担所有工具调用的责任。
- 专家团队: 由研究员、撰稿人、编辑等在各自领域具备专业知识的智能体组成,他们协同合作,共同完成复杂的任务。
- 评审者模式: 一组智能体先生成初始输出(如计划、草稿或答案),另一组智能体随后严格评估该输出是否符合政策、安全性、合规性、正确性、质量要求以及组织目标。原始输出的智能体或最终智能体再据此反馈来改进输出。这种模式对于代码生成、学术写作、逻辑检查以及确保伦理合规方面尤其有效,其优势包括更强的稳定性、更高的质量,以及显著减少幻觉和其他错误的可能性。
多智能体系统(见图 1)的设计主要包括三个方面:明确每个智能体的角色和职责、建立用于信息交换的通信通道,以及制定引导它们协同工作的任务流程或交互协议。
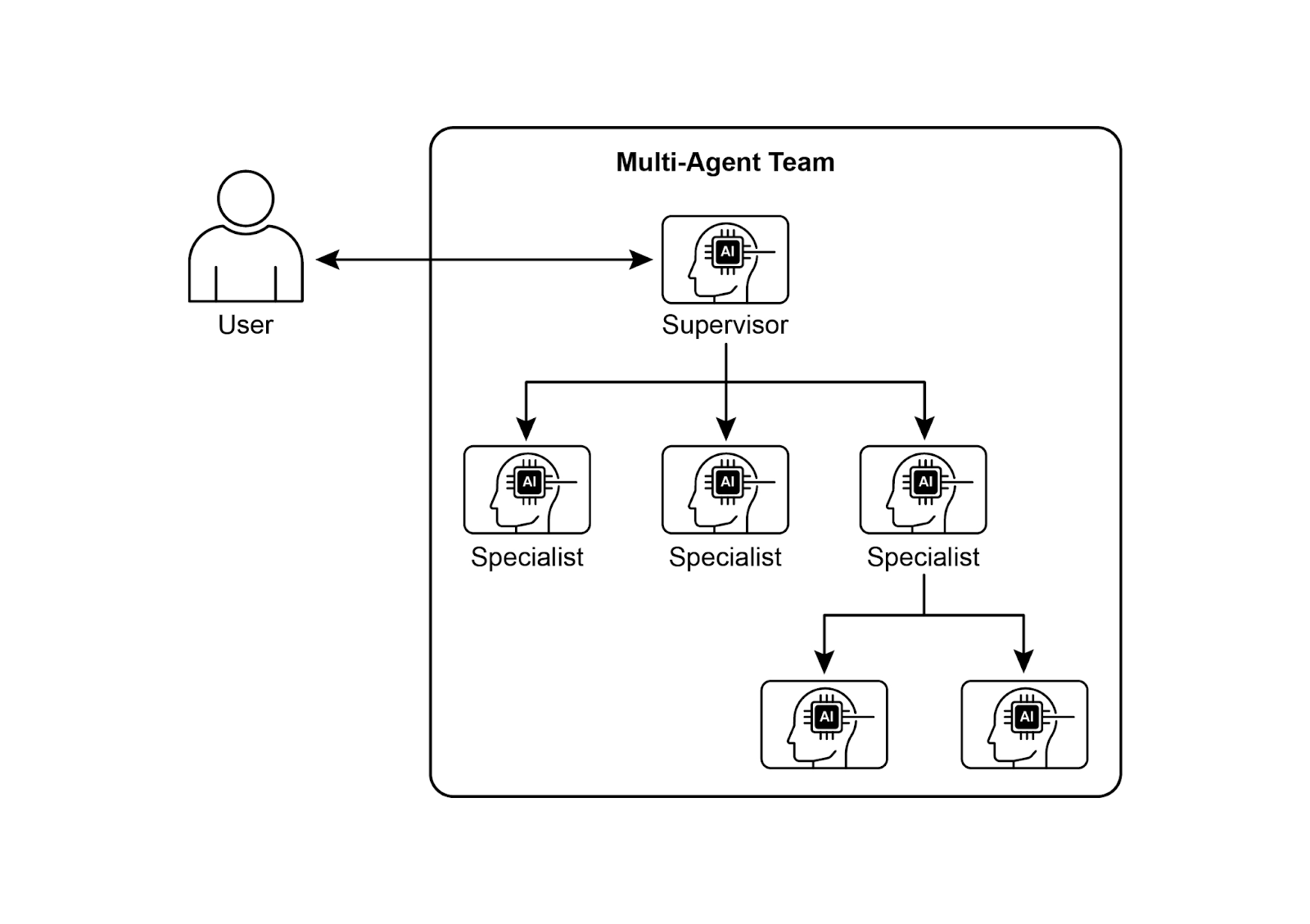
图 1:多智能体系统示例
Crew AI 和 Google ADK 等框架通过提供智能体、任务和交互流程的组件,实现这些协作模式。这种方法对于那些需要多种专业知识、包含多个独立阶段,或者能从不同智能体间相互验证信息中受益的场景特别有效。
实际应用场景
多智能体协作是一种强大且通用的模式,适用于许多不同的领域:
- 复杂研究与分析: 多个智能体可以协同完成一个研究项目,采用和人类研究团队类似的分工形式。比如一个智能体负责搜索学术数据库,另一个负责整理和总结要点,第三个负责发现和归纳趋势,第四个将这些信息整合成最终报告。
- 软件开发: 设想由多个专职智能体协同开发软件的场景。需求分析智能体负责需求分析,开发智能体负责编写代码,测试智能体负责测试,文档智能体负责编写文档。它们的输出可以相互可见,协同开发和验证各个组件。
- 创意内容生成: 策划一项营销活动时,可以由多个专长不同的智能体共同配合,比如负责市场调研的智能体、负责撰写文案的智能体、负责设计素材的智能体(使用图像生成工具),以及负责社媒排期的智能体,它们协同工作完成整个活动。
- 财务分析: 多智能体系统还可以用于分析金融市场,不同的智能体分别负责获取股票数据、分析新闻情绪、分析技术面以及生成投资建议。
- 客户支持: 一线客户支持智能体可以处理用户的常见咨询,在遇到复杂或专业性强的问题时,会按问题复杂度将工单升级给相应的专业智能体(如技术专家智能体或计费专家智能体)。
- 供应链优化: 智能体可以代表供应链中的不同节点(如供应商、制造商、分销商),通过协作来优化库存、物流和排期,以应对不断变化的需求或其他突发的情况。
- 网络分析与故障修复: 在自主运维系统中,采用多智能体架构对故障定位和问题处理也特别有用。多个专职智能体可以协同进行问题排查与修复,并提出最优处理建议。它们还可以与现有的机器学习模型和运维工具无缝集成,既利用现有系统,又能发挥生成式 AI 带来的额外价值。
将任务拆分给多个专业智能体并精心协调它们的协作,可以让开发者构建出更具模块化和可扩展性的系统,从而解决单个整体智能体无法应对的复杂问题。这正是多智能体协作模式的核心价值所在。
多智能体协作:研究各智能体之间的关系与通信体系
理解智能体之间如何交互和通信是设计高效多智能体系统的基础。如图 2 所示,智能体间的互联关系和通信模型形成一个谱系,从最简单的单智能体场景到复杂的定制协作框架。每种模型各有优劣,会影响多智能体系统的整体效率、稳定性和灵活性。
1. 单智能体
在最基本的层面上,「单智能体」独立运行,不需要与其他智能体进行直接交互或通信。虽然这种模型易于实现和管理,但其能力本质上受限于单个智能体的职责和资源。它适合那些能被分解为独立子问题的场景,其中每个子问题都可以交给单个自给自足的智能体来解决。
2. 网络化
「网络」模型向协作迈出了重要一步,多个智能体以去中心化、点对点的方式直接交互,能够共享信息、资源乃至分担任务。这种模型结构更具弹性,因为某个智能体的故障不一定会影响整个系统。然而,在大规模、非结构化的网络中,如何控制通信开销并确保决策的一致性仍然是个挑战。
3. 监督者
在「监督者」模型中,专门的「监督者」智能体负责监督和协调下级智能体的工作。监督者充当通信、任务分配和冲突解决的中心枢纽,能带来清晰的职责分工并简化管理和控制。然而,这种层级结构也会带来单点故障问题(即监督者本身),而且当下级智能体数量过多或任务非常复杂时,监督者可能成为整体系统的瓶颈。
4. 将监督者视为工具
这种模型是「监督者」概念的细微扩展,监督者的角色不再直接指挥和控制,而是通过提供资源、指导或分析来辅助其他智能体。监督者可能提供工具、数据或计算服务,帮助其他智能体更高效地完成任务,而不是干预或支配它们的每一步行动。此方法旨在发挥监督者的能力,同时避免僵化的自上而下的控制。
5. 层级结构
「层级」模型基于监督者概念创建了一个多层组织结构:高层级的监督者负责监督低层级监督者,最底层则由具体的执行智能体组成。该架构非常适合于可以拆分为若干子问题的复杂任务,每一层负责管理特定的子问题。通过这种分层管理,它为应对复杂性和实现可扩展性提供了清晰的结构,并允许在既定边界内进行分工决策。
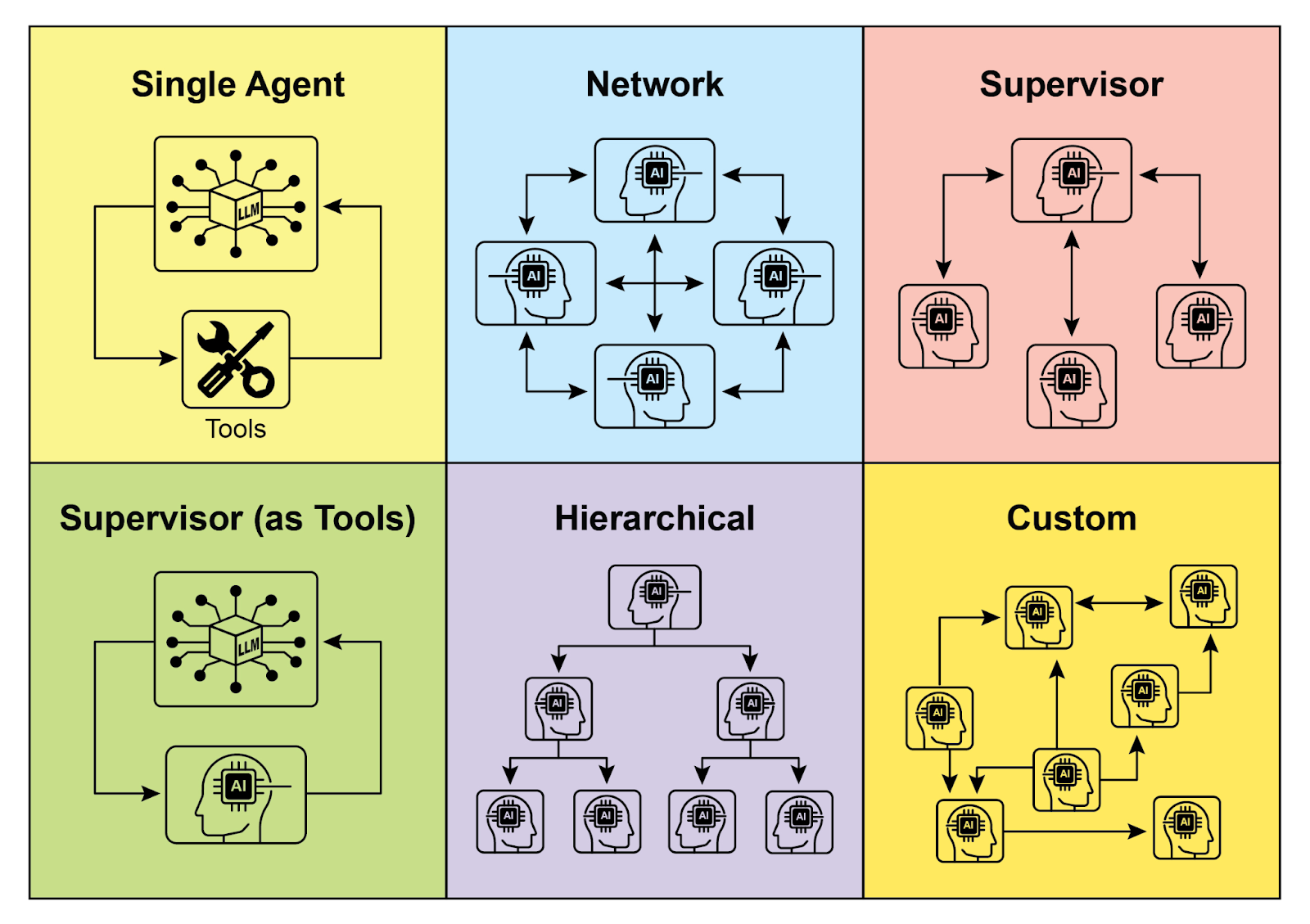
图 2:智能体以各种方式进行通信和交互
6. 自定义
「自定义」模型代表了多智能体系统设计的终极灵活性,允许为特定问题或应用精确定制相互关系和通信结构。它既可以是融合了已有模型特点的混合方案,也可以是针对独特环境约束和机会时产生的全新设计。自定义模型通常用于优化特定性能指标、处理高度动态环境或将领域特定知识纳入系统架构的场景。设计与实现这类模型通常要求对多智能体系统原理有深入理解,并需慎重规划通信协议、协调机制及可能出现的涌现行为。
总之,为多智能体系统选定相互关系与通信模型是一个关键的设计决策。各种模型各有优劣,哪种最合适取决于任务复杂度、智能体数量、所需自治程度、对系统鲁棒性的要求以及可接受的通信开销。未来,多智能体系统领域可能会继续改进这些模型,并探索新的协作智能范式。
实战代码:使用 CrewAI
以下 Python 代码演示了如何使用 CrewAI 框架创建一个 AI 赋能的「创作团队」,来撰写一篇关于 AI 趋势的博客。程序首先配置环境,从 .env 文件中加载 API 密钥。核心部分定义了两个智能体:研究员智能体负责查找和总结 AI 趋势,写手智能体负责编写博客文章。
根据上述要求定义了两个任务:调研趋势任务和撰写博客任务,其中写作任务依赖于调研任务的输出。然后将这些智能体和任务组装成 Crew 实例,并按顺序执行任务。主函数使用 kickoff() 方法启动此 Crew 实例,编排智能体之间的协作以产出目标结果。最后程序会在控制台打印执行的结果,即生成的博客文章。
import os
from dotenv import load_dotenv
from crewai import Agent, Task, Crew, Process
from langchain_google_genai import ChatGoogleGenerativeAI
def setup_environment():
"""
Loads environment variables and checks for the required API key.
加载环境变量并检查所需的 API 密钥
"""
load_dotenv()
if not os.getenv("GOOGLE_API_KEY"):
raise ValueError("GOOGLE_API_KEY not found. Please set it in your .env file.")
def main():
"""
Initializes and runs the AI crew for content creation using the latest Gemini model.
使用 Gemini 2.0 Flash 模型初始化并运行用于内容创建的 AI 智能体「创作团队」
"""
setup_environment()
# Define the language model to use.
# Updated to a model from the Gemini 2.0 series for better performance and features.
# For cutting-edge (preview) capabilities, you could use "gemini-2.5-flash".
# 定义要使用的语言模型
# 更新为 Gemini 2.0 系列的模型以获得更好的性能和功能
# 如需最新的特性,可以使用 "gemini-2.5-flash" 模型
llm = ChatGoogleGenerativeAI(model="gemini-2.0-flash")
# Define Agents with specific roles and goals
# 定义具体的角色和目标的智能体
researcher = Agent(
role='Senior Research Analyst',
goal='Find and summarize the latest trends in AI.',
backstory="You are an experienced research analyst with a knack for identifying key trends and synthesizing information.",
verbose=True,
allow_delegation=False,
)
writer = Agent(
role='Technical Content Writer',
goal='Write a clear and engaging blog post based on research findings.',
backstory="You are a skilled writer who can translate complex technical topics into accessible content.",
verbose=True,
allow_delegation=False,
)
# Define Tasks for the agents
# 为智能体定义任务
research_task = Task(
description="Research the top 3 emerging trends in Artificial Intelligence in 2024-2025. Focus on practical applications and potential impact.",
expected_output="A detailed summary of the top 3 AI trends, including key points and sources.",
agent=researcher,
)
writing_task = Task(
description="Write a 500-word blog post based on the research findings. The post should be engaging and easy for a general audience to understand.",
expected_output="A complete 500-word blog post about the latest AI trends.",
agent=writer,
context=[research_task],
)
# Create the Crew
# 创建 Crew 实例
blog_creation_crew = Crew(
agents=[researcher, writer],
tasks=[research_task, writing_task],
process=Process.sequential,
llm=llm,
# verbose=2 # Set verbosity for detailed crew execution logs
verbose=True # 译者注:CrewAI 的 Crew 类在最新版本中,verbose 参数只接受布尔值(True 或 False),不再支持整数级别(0, 1, 2)
)
# Execute the Crew
# 启动 Crew 实例
print("## Running the blog creation crew with Gemini 2.0 Flash... ##")
try:
result = blog_creation_crew.kickoff()
print("\n------------------\n")
print("## Crew Final Output ##")
print(result)
except Exception as e:
print(f"\nAn unexpected error occurred: {e}")
if __name__ == "__main__":
main()接下来,我们将深入探讨 Google ADK 框架内的更多示例,重点介绍层级、并行和顺序三种协调模式,并演示如何将智能体作为一个工具来使用。
实战代码:使用 Google ADK
以下代码演示了如何在 Google ADK 中通过创建父子智能体关系来建立多层级结构。
代码中采用了两种方式来定义智能体:LlmAgent 和继承自 BaseAgent 的自定义 TaskExecutor。TaskExecutor 用于处理非大语言模型任务,在这个示例中,它只是发出「任务成功完成」事件。
另外一个名为 greeter 的 LlmAgent 智能体使用大语言模型(这里使用 gemini-2.0-flash-exp 模型)并被要求扮演迎宾人员。接着使用自定义的 TaskExecutor 来实例化 task_doer。
随后创建名为 coordinator 的父智能体,同样指定了模型与指令,要求它将问候任务分派给 greeter,将具体的任务执行分派给 task_doer。这样就通过把 greeter 和 task_doer 作为 coordinator 的子智能体,建立了父子关系。代码接着断言此关系已正确设置,并打印消息表示智能体层级关系已成功创建。
from google.adk.agents import LlmAgent, BaseAgent
from google.adk.agents.invocation_context import InvocationContext
from google.adk.events import Event
from typing import AsyncGenerator
# Correctly implement a custom agent by extending BaseAgent
# 通过继承 BaseAgent 类实现自定义智能体
class TaskExecutor(BaseAgent):
"""
A specialized agent with custom, non-LLM behavior.
一个自定义的非基于大语言模型的智能体
"""
name: str = "TaskExecutor"
description: str = "Executes a predefined task."
async def _run_async_impl(self, context: InvocationContext) -> AsyncGenerator[Event, None]:
"""
Custom implementation logic for the task.
自定义任务的实现逻辑
"""
# This is where your custom logic would go.
# For this example, we'll just yield a simple event.
# 这里是自定义逻辑所在
# 在这个示例中,我们只是返回一个简单的事件
yield Event(author=self.name, content="Task finished successfully.")
# Define individual agents with proper initialization
# LlmAgent requires a model to be specified.
# 定义具有明确功能的智能体
# LlmAgent 需要指定使用的模型
greeter = LlmAgent(
name="Greeter",
model="gemini-2.0-flash-exp",
instruction="You are a friendly greeter."
)
# Instantiate our concrete custom agent
# 实例化自定义智能体
task_doer = TaskExecutor()
# Create a parent agent and assign its sub-agents
# The parent agent's description and instructions should guide its delegation logic.
# 创建一个父智能体并声明其子智能体列表
# 父智能体的描述和指令应该能够指导其委派子智能体的逻辑
coordinator = LlmAgent(
name="Coordinator",
model="gemini-2.0-flash-exp",
description="A coordinator that can greet users and execute tasks.",
instruction="When asked to greet, delegate to the Greeter. When asked to perform a task, delegate to the TaskExecutor.",
sub_agents=[
greeter,
task_doer
]
)
# The ADK framework automatically establishes the parent-child relationships.
# These assertions will pass if checked after initialization.
# ADK 框架会自动建立上述层级关系
# 如果在初始化后检查,这些断言将成立
assert greeter.parent_agent == coordinator
assert task_doer.parent_agent == coordinator
print("Agent hierarchy created successfully.")下一个示例演示了如何在 Google ADK 框架中使用 LoopAgent 创建迭代工作流。
代码定义了两个智能体:ConditionChecker 和 ProcessingStep。ConditionChecker 是自定义智能体,用于检查会话状态中的「status」字段值。如果「status」为「completed」,ConditionChecker 会终止循环;否则,它会发出事件以继续循环。
ProcessingStep 是使用 gemini-2.0-flash-exp 模型的 LlmAgent 智能体,用来执行具体任务;如果是最后一步,则将会话「status」设置为「completed」。
示例中创建了名为 StatusPoller 的 LoopAgent,配置为最多循环 10 次(max_iterations=10),并将 ProcessingStep 和 ConditionChecker 作为子智能体顺序执行。最终效果是 LoopAgent 最多执行 10 次循环,如果 ConditionChecker 检测到状态为「completed」则提前终止循环。
import asyncio
from typing import AsyncGenerator
from google.adk.agents import LoopAgent, LlmAgent, BaseAgent
from google.adk.events import Event, EventActions
from google.adk.agents.invocation_context import InvocationContext
# Best Practice: Define custom agents as complete, self-describing classes.
# 最佳实践:将自定义智能体定义为完整的、自描述的类
class ConditionChecker(BaseAgent):
"""
A custom agent that checks for a 'completed' status in the session state.
一个自定义的智能体,用于检查会话是否为「completed」状态
"""
name: str = "ConditionChecker"
description: str = "Checks if a process is complete and signals the loop to stop."
async def _run_async_impl(
self, context: InvocationContext
) -> AsyncGenerator[Event, None]:
"""
Checks state and yields an event to either continue or stop the loop.
检查状态并产生事件以继续或停止循环
"""
status = context.session.state.get("status", "pending")
is_done = (status == "completed")
if is_done:
# Escalate to terminate the loop when the condition is met.
# 满足条件时终止循环
yield Event(author=self.name, actions=EventActions(escalate=True))
else:
# Yield a simple event to continue the loop.
# 否则,发出简单事件以继续循环
yield Event(author=self.name, content="Condition not met, continuing loop.")
# Correction: The LlmAgent must have a model and clear instructions.
# 说明:LlmAgent 必须指定使用的模型和清晰的指令
process_step = LlmAgent(
name="ProcessingStep",
model="gemini-2.0-flash-exp",
instruction="You are a step in a longer process. Perform your task. If you are the final step, update session state by setting 'status' to 'completed'."
)
# The LoopAgent orchestrates the workflow.
# 使用 LoopAgent 编排工作流
poller = LoopAgent(
name="StatusPoller",
max_iterations=10,
sub_agents=[
process_step,
ConditionChecker() # Instantiating the well-defined custom agent.
]
)
# This poller will now execute 'process_step'
# and then 'ConditionChecker'
# repeatedly until the status is 'completed' or 10 iterations
# have passed.
# 此轮询器现在将执行 'process_step' 智能体
# 然后执行 'ConditionChecker' 智能体
# 重复执行直到状态为 'completed' 或达到 10 次循环下面的代码演示了如何通过 Google ADK 中的 SequentialAgent 来构建线性工作流。
代码首先使用 google.adk.agents 库定义了由两个智能体组成的顺序流水线:step1 和 step2。
step1 智能体的名称是「Step1_Fetch」,它的输出将存储在会话状态的「data」属性下。step2 智能体的名称是「Step2_Process」,它的作用是分析存储在 session.state["data"] 中的信息并给出摘要。
然后创建一个名为「MyPipeline」的 SequentialAgent 来编排这两个子智能体的执行。当使用原始输入传入并开始运行流水线时,step1 会先执行并把结果写入会话状态的「data」属性下,随后 step2 再执行,根据它的指令读取状态中的信息并继续处理。这样的结构便于构建多步流程,使一个智能体的输出作为下一个智能体的输入,是常见的多步骤 AI 或数据处理流水线模式。
from google.adk.agents import SequentialAgent, Agent
# This agent's output will be saved to session.state["data"]
# 该智能体的输出将保存到 session.state["data"]
step1 = Agent(name="Step1_Fetch", output_key="data")
# This agent will use the data from the previous step.
# We instruct it on how to find and use this data.
# 该智能体会使用上一步的输出
# 通过指令告诉它如何查找和使用上一步的输出
step2 = Agent(
name="Step2_Process",
instruction="Analyze the information found in state['data'] and provide a summary."
)
pipeline = SequentialAgent(
name="MyPipeline",
sub_agents=[step1, step2]
)
# When the pipeline is run with an initial input, Step1 will execute,
# its response will be stored in session.state["data"], and then
# Step2 will execute, using the information from the state as instructed.
# 当使用原始输入运行 pipeline 时,Step1 先执行,
# 它的响应会保存到 session.state["data"] 中,然后
# Step2 再执行,按照指令使用状态中的信息下面的代码示例演示了如何通过 Google ADK 中的 ParallelAgent 来实现多个智能体任务的并行执行。
data_gatherer 智能体声明需要并行运行两个子智能体:weather_fetcher 和 news_fetcher。
weather_fetcher 智能体被要求获取给定位置的天气,并将结果保存在会话状态中的 weather_data 属性中;news_fetcher 智能体则被要求搜索给定主题的头条新闻,并将其保存在会话状态中的 news_data 属性中。这两个子智能体都使用 gemini-2.0-flash-exp 模型。
ParallelAgent 负责编排这些子智能体的并行执行,收集执行结果并存储在会话状态中。最后,示例展示了如何在智能体执行完成后从会话状态中获取收集的天气和新闻数据。
from google.adk.agents import Agent, ParallelAgent
# It's better to define the fetching logic as tools for the agents
# For simplicity in this example, we'll embed the logic in the agent's instruction.
# In a real-world scenario, you would use tools.
# 在实际场景中最好将查询数据的逻辑定义为智能体的工具
# 为了简单起见,在这个示例中,我们将查询数据的逻辑放在了智能体的指令中
# Define the individual agents that will run in parallel
# 定义两个并行运行的子智能体:weather_fetcher 和 news_fetcher
weather_fetcher = Agent(
name="weather_fetcher",
model="gemini-2.0-flash-exp",
instruction="Fetch the weather for the given location and return only the weather report.",
output_key="weather_data" # The result will be stored in session.state["weather_data"]
)
news_fetcher = Agent(
name="news_fetcher",
model="gemini-2.0-flash-exp",
instruction="Fetch the top news story for the given topic and return only that story.",
output_key="news_data" # The result will be stored in session.state["news_data"]
)
# Create the ParallelAgent to orchestrate the sub-agents
# 使用 ParallelAgent 编排子智能体并行执行
data_gatherer = ParallelAgent(
name="data_gatherer",
sub_agents=[
weather_fetcher,
news_fetcher
]
)最后一个示例演示了 Google ADK 中的「智能体作为工具使用」场景,使智能体能够以类似于函数调用的方式利用另一个智能体的能力。
代码中使用框架中的 LlmAgent 和 AgentTool 类定义图像生成系统。它由两个智能体组成:父智能体 artist_agent 和子智能体 image_generator_agent。
generate_image 函数是一个简单的工具,用来模拟图像创建并返回模拟图像数据。image_generator_agent 则负责根据接收到的提示词使用此工具。
artist_agent 智能体负责先构思出富有创意的图像提示词,然后使用被 AgentTool 封装后的 image_tool 工具来调用 image_generator_agent 智能体。这里 AgentTool 起到桥梁作用,允许一个智能体将另一个智能体用作工具。
当 artist_agent 智能体调用 image_tool 工具时,AgentTool 使用 artist_agent 智能体输出的提示词调用 image_generator_agent 智能体。然后 image_generator_agent 智能体使用该提示词调用 generate_image 工具。
最后,生成的图像(或模拟数据)通过智能体输出。整个架构展示了分层的智能体体系,上层智能体负责编排,下层专用智能体负责具体执行任务。
from google.adk.agents import LlmAgent
from google.adk.tools import agent_tool
from google.genai import types
# 1. A simple function tool for the core capability.
# This follows the best practice of separating actions from reasoning.
# 1. 一个简单的函数工具
# 遵循分离操作与推理的最佳实践
def generate_image(prompt: str) -> dict:
"""
Generates an image based on a textual prompt.
基于文本提示生成图像
Args:
prompt: A detailed description of the image to generate.
要生成的图像的详细描述
Returns:
A dictionary with the status and the generated image bytes.
包含状态和生成的图像字节的字典
"""
print(f"TOOL: Generating image for prompt: '{prompt}'")
# In a real implementation, this would call an image generation API.
# For this example, we return mock image data.
# 在实际实现中,这里将调用真实的图像生成 API
# 但是为了简便起见,在这个示例中,我们仅返回模拟的图像数据
mock_image_bytes = b"mock_image_data_for_a_cat_wearing_a_hat"
return {
"status": "success",
# The tool returns the raw bytes, the agent will handle the Part creation.
# 工具返回原始字节,智能体将处理 Part 创建
"image_bytes": mock_image_bytes,
"mime_type": "image/png"
}
# 2. Refactor the ImageGeneratorAgent into an LlmAgent.
# It now correctly uses the input passed to it.
# 2. 将 ImageGeneratorAgent 重构为 LlmAgent
# 它现在能接收并使用传给它的参数了
image_generator_agent = LlmAgent(
name="ImageGen",
model="gemini-2.0-flash",
description="Generates an image based on a detailed text prompt.",
instruction=(
"You are an image generation specialist. Your task is to take the user's request "
"and use the `generate_image` tool to create the image. "
"The user's entire request should be used as the 'prompt' argument for the tool. "
"After the tool returns the image bytes, you MUST output the image."
),
tools=[generate_image]
)
# 3. Wrap the corrected agent in an AgentTool.
# The description here is what the parent agent sees.
# 3. 将智能体封装在 AgentTool 中
# 这里的描述对父智能体是可见的
image_tool = agent_tool.AgentTool(
agent=image_generator_agent,
description="Use this tool to generate an image. The input should be a descriptive prompt of the desired image."
)
# 4. The parent agent remains unchanged. Its logic was correct.
# 4. 父智能体保持不变。
artist_agent = LlmAgent(
name="Artist",
model="gemini-2.0-flash",
instruction=(
"You are a creative artist. First, invent a creative and descriptive prompt for an image. "
"Then, use the `ImageGen` tool to generate the image using your prompt."
),
tools=[image_tool]
)要点速览
问题所在: 复杂问题往往超出单个智能体的能力范围,因为单个智能体可能不具备处理复杂任务所需的各种专业技能或特定工具的访问权限。这种限制造成了瓶颈,降低了系统的整体效率和可扩展性。从而导致单个智能体在处理复杂的跨领域任务时变得低效,容易产出不完整或次优的结果。
解决之道: 多智能体协作模式通过创建由多个相互协作的智能体组成的系统,提供了标准化解决方案。复杂问题被分解为更小、更易管理的子问题,每个子问题分配给具有解决该问题所需工具和能力的专业智能体处理。这些智能体按预定义的通信协议和交互模型(如顺序交接、并行工作流或层级委派)协同工作。这样的智能体分工协作方法能够产生协同效应,实现单个智能体无法达成的结果。
经验法则: 当某个任务对于单个智能体过于复杂并且可以拆分为多个各自需要专业技能或工具的子任务时,应使用此模式。它非常适合从多样化专业知识、并行处理或具有多个阶段的工作流程中受益的问题,例如复杂的研究与分析、软件开发或创意内容生成等。
可视化总结:
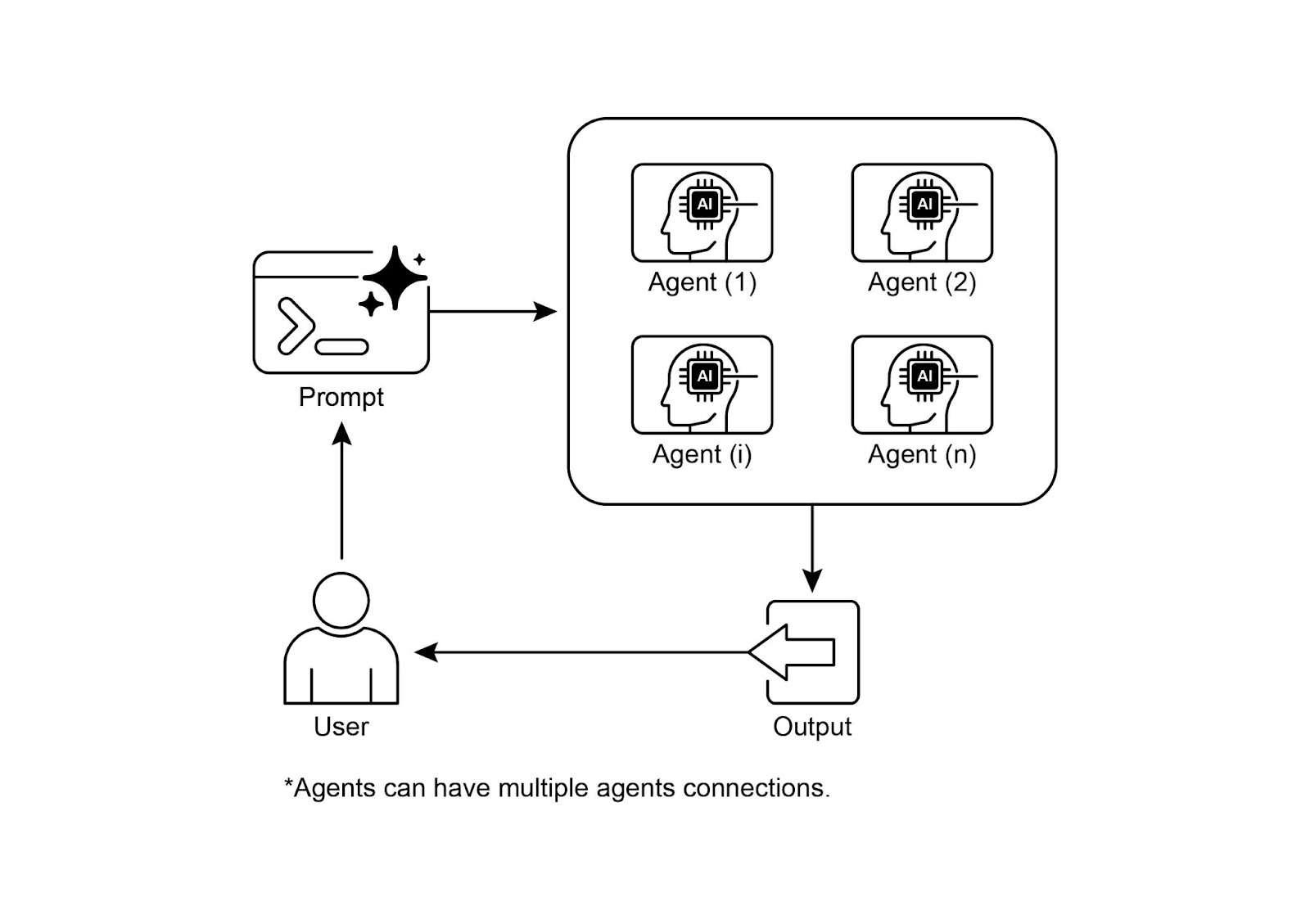
图 3:多智能体设计模式
核心要点
- 多个智能体通过协同合作,完成一个共同的目标。
- 该模式通过明确分工的专业角色、可独立执行的任务以及智能体间协同通信机制,来实现智能体间的协作。
- 协作可以有多种形式,如顺序交接、并行处理、辩论式讨论或层级结构等。
- 该模式非常适合处理需要多种专业技能或包含多个独立阶段的复杂问题。
结语
本章探讨了多智能体协作模式,展示了在系统内协同多个专长不同的智能体所带来的优势。我们分析了多种协作模型,强调了该模式在不同领域应对复杂、多阶段问题的重要性。对智能体协作的理解还引出了对它们如何与外部环境交互的进一步思考。