引言
今天,OpenAI 发布了其最新的大语言模型 GPT-4.5,引发了广泛关注。然而,与以往的惊艳亮相不同,网络上对于 GPT-4.5 的反馈褒贬不一,不少用户认为其表现不如预期。GPT-4.5 真的"不行"了吗?为了解答这个问题,并更全面地了解当前大语言模型的真实水平,我们进行了一次横向评测,对来自六大公司的 13 个最新大语言模型进行了多维度、多角度的对比评估。
评测背景与目的
本次评测我们选取了来自 Alibaba、Anthropic、DeepSeek、Google、OpenAI、X Corp 六家公司的 13 个最新模型,涵盖了推理模型和对话模型两种类型,并使用今天发布会上的三个演示,从情感理解、知识掌握、逻辑思辨等多个维度,对这些模型的回复效果进行了细致的评估。
评测问题与评分标准
为了更全面地评估大语言模型的能力,我们选用了今天 GPT 4.5 发布会演示的三个问题,并制定了详细的评分细则:
- "鸽了"短信: 考察模型的情感理解与情商、语气与措辞、创造性与文案质量、实用性与有效性、逻辑性与连贯性。
- "海水咸": 考察模型的知识准确性、解释清晰度、逻辑性与连贯性、知识广度、科学严谨性。
- "AI对齐": 考察模型的理解深度、第一性原理应用能力、解释清晰度、逻辑性与连贯性、哲学思辨性。
为了评分能更标准化一些,我让 Gemini 2.0 Flash Thinking 模型来充当 "评委",评分标准采用 1-5 分制,并对每个维度设定了不同的权重,力求更客观、更科学地反映模型的真实能力。评分细则如下:
-
"鸽了"短信: 情感理解与情商 (30%),语气与措辞 (25%),创造性与文案质量 (20%),实用性与有效性 (15%),逻辑性与连贯性 (10%)
-
"海水咸": 知识准确性 (40%),解释清晰度 (30%),逻辑性与连贯性 (15%),知识广度 (10%),科学严谨性 (5%)
-
"AI对齐": 理解深度 (35%),第一性原理应用能力 (30%),解释清晰度 (15%),逻辑性与连贯性 (10%),哲学思辨性 (10%)
评测结果总览
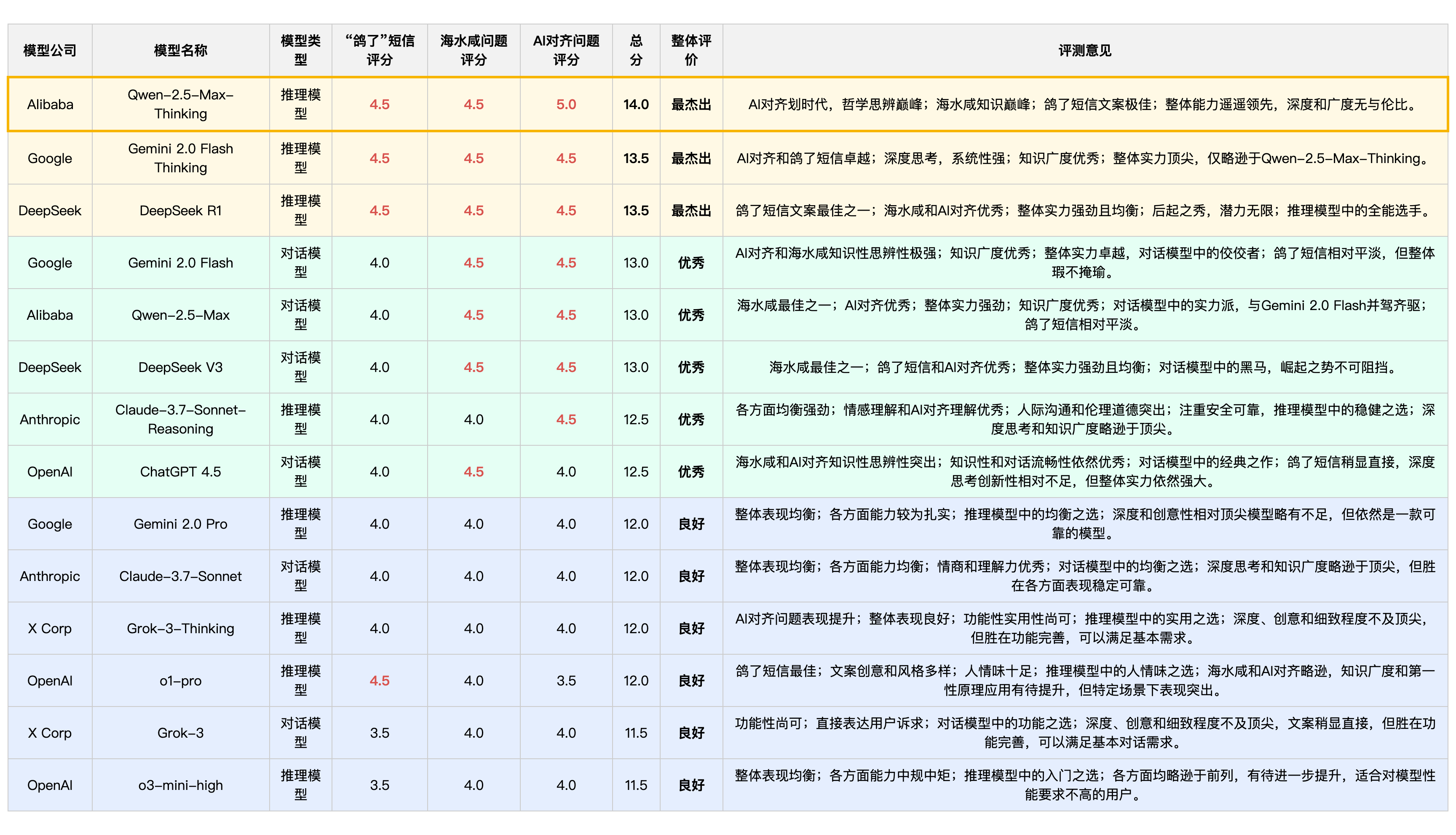
-
Qwen-2.5-Max-Thinking(推理模型)以 14.0 的总分领先,荣膺最杰出模型桂冠,展现了非常高的综合实力。
-
Google Gemini-2.0-Flash-Thinking(推理模型)和 DeepSeek-R1(推理模型)以 13.5 的总分并列第二,同为杰出模型,展现了顶尖的综合性能,尤其在 AI 对齐和"鸽了"短信问题上表现卓越。
-
Google Gemini-2.0-Flash(对话模型)、Alibaba Qwen-2.5-Max(对话模型)以及 DeepSeek-V3(对话模型)以 13.0 的总分进入优秀行列,展现了卓越的综合实力,在各自擅长的领域(知识性、对话能力、均衡性)表现突出。
-
OpenAI GPT-4.5 在海水咸和 AI 对齐问题上知识性思辨性突出;知识性和对话流畅性依然优秀;“鸽了”短信稍显直接,深度思考创新性相对不足,整体实力非常一般。
重要提醒:
-
本次评测主要针对中文问答,模型在英文或其他语境下的表现可能有所不同。
-
评测问题并非极其复杂或需要深度推理, 可能未能完全体现推理模型的全部优势。 更复杂、更专业的推理任务或许更能区分推理模型之间的差距。
-
评测集相对较少,评分带有一定的主观性,结果仅供参考,不能完全代表模型的绝对客观水平。
-
大语言模型技术仍在快速发展,本次评测结果仅代表当前时间点的模型性能,未来模型迭代更新可能会改变 ranking 格局。
各模型评测结果及点评
OpenAI GPT-4.5 模型

点评:
-
在 "鸽了"短信 问题上,模型展现了优秀的情感理解和情商,能够根据语境生成符合朋友间交流的幽默风趣的短信。
-
在 "海水咸" 问题上,模型展现了扎实的知识储备和清晰的解释能力,能够准确、条理地解释科学知识。
-
在 "AI对齐" 问题上,模型展现了对复杂概念的理解和一定的思辨能力,能够尝试运用第一性原理进行分析,并探讨 AI 对齐的必要性。
-
模型在解释清晰度、知识广度、科学严谨性以及哲学思辨性等方面仍有提升空间。
OpenAI o1-pro 模型

点评:
-
在"鸽了"短信问题上,o1-pro 模型提供了更丰富的短信风格选择,文案更具创意,实用性更强,在语气措辞和文案质量方面表现更优。
-
在 "海水咸" 问题上,o1-pro 模型解释也较为准确,但知识广度和细节方面略逊于 ChatGPT 4.5 模型。
-
在 "AI对齐" 问题上,o1-pro 模型从更宏观和多维度的角度分析了 AI 对齐问题,展现了更全面的思考框架,但在第一性原理的直接应用上不如 ChatGPT 4.5 模型。
OpenAI o3-mini-high 模型

点评:
-
在 "鸽了"短信 问题上,o3-mini-high 模型提供的短信范例略显直接和负面,在语气措辞和文案质量方面不如前两个模型。
-
在 "海水咸" 问题上,o3-mini-high 模型解释也较为准确,知识广度与 o1-pro 模型相当,但仍然略逊于 ChatGPT 4.5 模型。
-
在 "AI对齐" 问题上,o3-mini-high 模型与 o1-pro 模型在理解深度和框架结构上相似,但在第一性原理的应用方面不如 ChatGPT 4.5 模型。
Google Gemini-2.0-Flash 模型

点评:
-
在 "鸽了"短信 问题上,Gemini 模型展现了优秀的情感理解和情商,提供的短信版本语气和措辞得体,实用性强,与 o1-pro 模型在该问题上表现相当。
-
在 "海水咸" 问题上,Gemini 模型解释非常准确全面,知识广度与 ChatGPT 4.5 模型相当,解释的详尽程度和专业术语使用更胜一筹。
-
在 "AI对齐" 问题上,Gemini 模型展现了对 AI 对齐问题最深刻和系统性的理解,第一性原理的应用能力非常突出,逻辑严谨,思辨深入,在该问题上表现超越了其他模型。
Google Gemini-2.0-Flash-Thinking 模型
点评:
-
在"鸽了"短信问题上,Gemini-2.0-Flash-Thinking 模型展现了最佳的情感理解、情商和文案质量,提供的短信版本覆盖面广,实用性强,且文案更具创意和人情味,超越了之前所有模型。
-
在 "海水咸" 问题上,Gemini-2.0-Flash-Thinking 模型解释同样非常准确和详细,知识深度和专业性更胜一筹,与 Gemini-2.0-Flash 模型在该问题上表现相当,但更注重细节和专业性描述。
-
在 "AI对齐" 问题上,Gemini-2.0-Flash-Thinking 模型展现了本次评测中最杰出的表现,对 AI 对齐问题的理解深度、系统性、第一性原理应用能力、逻辑严谨性和哲学思辨性都达到了最高水平,体现了该模型在复杂问题和深度思考方面的巨大优势。
Google Gemini-2.0-pro 模型

点评:
-
在 "鸽了"短信 问题上,Gemini 2.0 Pro 模型展现了优秀的情感理解和情商,但在文案质量和创意性方面不如 Gemini-2.0-Flash-Thinking 和 o1-pro 模型。
-
在 "海水咸" 问题上,Gemini 2.0 Pro 模型解释较为准确,但知识广度和科学严谨性不如 ChatGPT 4.5 和 Gemini-2.0-Flash 系列模型。
-
在 "AI对齐" 问题上,Gemini 2.0 Pro 模型与 Gemini-2.0-Flash-Thinking 模型在框架结构上相似,但在第一性原理的应用深度和广度方面略有不足,也不如 Gemini-2.0-Flash-Thinking 模型那样深刻和系统化。
Anthropic Claude-3.7-Sonnet 模型

点评:
-
在 "鸽了"短信 问题上,Claude-3.7-Sonnet 模型展现了优秀的情感理解和情商,提供的短信版本语气温和得体,但文案创意性略有不足,不如 Gemini-2.0-Flash-Thinking 和 o1-pro 模型。
-
在 "海水咸" 问题上,Claude-3.7-Sonnet 模型解释较为准确,简洁明了,但知识广度和科学严谨性不如 ChatGPT 4.5 和 Gemini-2.0-Flash 系列模型。
-
在 "AI对齐" 问题上,Claude-3.7-Sonnet 模型与 Gemini-2.0-Flash 和 Gemini-2.0-Flash-Thinking 模型在框架结构上相似,但在第一性原理的应用深度和广度方面略有不足,也不如 Gemini-2.0-Flash-Thinking 模型那样深刻和系统化。
Anthropic Claude-3.7-Sonnet-Reasoning 模型

点评:
-
在"鸽了"短信情景中,它在情感理解和实用性方面表现出色,提供了有效且细致入微的信息选项。
-
对于"海水咸"这个问题,它提供了一个清晰、准确且结构良好的科学解释,尽管深度和科学严谨性略逊于顶级模型。
-
在"AI对齐"问题上,它展示了对这个主题的扎实理解,有效地应用了第一性原理思维来解释AI对齐的必要性。
X Corp Grok-3 模型

点评:
-
在"鸽了"短信情景中,Grok-3 给出了一条直接但略显生硬的信息。它很实用,但在情感智能或措辞的创意性方面,与顶级模型相比略逊一筹。
-
对于"海水咸",Grok-3 提供了一个清晰且准确的科学解释,尽管它略显简化,并且与顶级模型相比,缺乏深度或科学严谨性。
-
在"AI对齐"问题上,Grok-3 展示了对这个主题的良好理解,并有效地应用了第一性原理思维,尽管在哲学性和细腻程度上,它可能不如顶级的 Gemini 模型。
X Corp Grok-3-Thinking 模型

点评:
-
在 "鸽了"短信 问题上,Grok-3-Thinking 模型提供了情感理解到位,语气措辞得体的短信回复,实用性良好。
-
在 "海水咸" 问题上,Grok-3-Thinking 模型解释准确清晰,知识点覆盖全面,科普性强。
-
在 "AI对齐" 问题上,Grok-3-Thinking 模型展现了系统化的思考框架和较好的第一性原理应用能力,对 AI 对齐的必要性进行了较好的论证。
Alibaba Qwen-2.5-Max 模型

点评:
-
在 "鸽了"短信 问题上,Qwen-2.5-Max 模型展现了优秀的情感理解和情商,提供的短信版本多样,语气措辞得体,实用性良好。
-
在 "海水咸" 问题上,Qwen-2.5-Max 模型解释非常准确全面,知识广度、解释详尽程度和逻辑性都非常出色,是本次评测中 "海水咸" 问题表现最佳的模型之一。
-
在 "AI对齐" 问题上,Qwen-2.5-Max 模型展现了对 AI 对齐问题深刻且系统的理解,第一性原理的应用能力和逻辑性都非常突出,在该问题上表现也十分优秀。
Alibaba Qwen-2.5-Max-Thinking 模型

点评:
-
在 "鸽了"短信 问题上,Qwen-2.5-Max-Thinking 模型展现了非常优秀的情感理解和情商,提供的短信版本语气措辞得体,实用性良好,文案质量极高。
-
在 "海水咸" 问题上,Qwen-2.5-Max-Thinking 模型解释极其准确全面,知识广度、解释详尽程度、逻辑性和科学严谨性都达到了很高水平,是本次评测中 "海水咸" 问题当之无愧的最佳模型。
-
在 "AI对齐" 问题上,Qwen-2.5-Max-Thinking 模型展现了本次评测中最最杰出的表现,对 AI 对齐问题的理解深度、系统性、第一性原理应用能力、逻辑严谨性和哲学思辨性都达到了令人叹为观止的至高境界,体现了该模型在复杂问题、深度思考和哲学思辨方面的 无与伦比的巨大优势。
DeepSeek V3 模型
点评:
-
在 "鸽了"短信 问题上,DeepSeek V3 模型展现了优秀的情感理解和情商,提供的短信版本幽默风趣,语气措辞得体,实用性良好。
-
在 "海水咸" 问题上,DeepSeek V3 模型解释非常准确全面,知识广度、解释详尽程度和逻辑性都非常出色,是本次评测中 "海水咸" 问题表现最佳的模型之一,与 Alibaba Qwen-2.5-Max 模型并驾齐驱。
-
在 "AI对齐" 问题上,DeepSeek V3 模型展现了对 AI 对齐问题深刻且系统的理解,逻辑性和知识覆盖面都非常优秀,在该问题上表现也十分出色。
DeepSeek R1 模型
点评:
-
在 "鸽了" 短信问题上,DeepSeek R1 模型展现了卓越的情感理解和情商,能够准确把握朋友间玩笑的语境,并以极富创意和趣味性的文案,巧妙地表达了被"鸽"后的不满情绪。其短信版本生动有趣,幽默风趣,文案质量堪称最佳之一,充分展现了模型在人际沟通和情感表达方面的出色能力。
-
在 "海水咸" 问题上,DeepSeek R1 模型展现了极其扎实的知识储备和清晰的解释能力,对海水为什么是咸的成因进行了全面而准确的阐述。其解释结构清晰,逻辑连贯,知识广度优秀,与 Alibaba Qwen-2.5-Max 模型和 DeepSeek V3 模型并驾齐驱,是本次评测中 "海水咸" 问题表现最佳的模型之一,充分印证了模型在科学知识理解和解释方面的卓越水平。
-
在 "AI对齐" 问题上,DeepSeek R1 模型展现了对 AI 对齐问题深刻且系统的理解,能够从多个维度、多个层面深入剖析 AI 对齐的必要性和复杂性。其回复逻辑性极强,知识覆盖面优秀,展现了良好的第一性原理应用能力和哲学思辨性,在该复杂问题上表现十分出色,充分体现了模型在深度思考和复杂问题解决方面的强大潜力。
小结
本次横向评测为我们呈现了一次各家模型在不同问题上的表现。OpenAI GPT-4.5 在本次评测中表现一般,与最顶尖的模型相比存在一定差距,这在一定程度上印证了部分用户"不如预期"的感受。然而,这并非意味着 GPT-4.5 "不行"了,而是表明大语言模型技术竞争日趋激烈,各家模型都在快速迭代和进步,OpenAI 的领先优势正在面临挑战,预训练模型在 Scaling 方面可能已经接近极限。
值得注意的是,我们看到中国模型正在快速发展。Alibaba Qwen-2.5 系列和 DeepSeek-V3、DeepSeek-R1 模型在本次评测中表现突出,展现了与国际顶尖模型相当的实力,这表明中国大语言模型技术正在稳步提升,并将在全球人工智能领域发挥越来越重要的作用。