本周反复出现的一个词,是基建。
AlphaGo 问世 10 年,Demis Hassabis 回顾了从围棋到蛋白质折叠、数学证明的演化路径。他给出的判断很明确:Gemini 的多模态感知能力,正在和 AlphaGo 那套逻辑规划能力靠近。AI 的角色,也在从工具走向协同科学家。应用层另一边,OpenClaw 已经超越 React,成为 GitHub 历史上 Star 最多的项目。它不只是一个开源工具,更像一套正在下沉的 Agent 基础设施。
从个人开发者的六层架构治理,到企业级 Code Review 的三代演进,再到黄仁勋提出的 AI 五层蛋糕,这期内容其实都在回答同一个问题:当 AI 编程能力慢慢变成标配,真正拉开差距的,往往是你搭了什么样的基建。
这周我也一直在折腾这件事。我把主要精力放在用 Skills 搭建个人内容工作流上,试着把内容输入、整理、深度阅读、基于个人画像的创作、多平台发布和数据分析串成一条链路。系统还在调,但我已经很明显地感受到,一旦工具开始互相配合,事情就不一样了。这也是我读完这期后最强烈的共鸣。

十年之后,AGI 的方向越来越清晰

本周有一篇文章我反复读了两遍。
Google DeepMind 创始人 Demis Hassabis 亲笔回顾了 AlphaGo 十年。他没有只停留在那枚传奇的 Move 37,而是把重点放回到一套通用的搜索与推理方法。这套方法后来进入 AlphaFold,去解决困扰生物学家 50 年的蛋白质折叠问题;进入 AlphaProof,帮 AI 拿到国际数学奥林匹克银牌和金牌水平的成绩;也进入 AlphaEvolve,找到了比人类方案更优的矩阵乘法算法。
让我反复回看的,不只是这些结果,而是里面那个很稳定的模式:同一套底层方法,能在完全不同的领域里继续奏效。围棋、蛋白质折叠、数学证明、算法发现,看起来差得很远,但背后都离不开搜索与推理。这不是一堆专用系统碰巧拼在一起,而是一套通用方法在不同场景里的迁移。
Demis 对 AGI 的判断也讲得很直白:未来的 AI,不会是多模态感知和逻辑规划各走各的,而是两条线慢慢汇合。Gemini 负责理解世界,AlphaGo 代表在世界中规划和行动的能力。两者一旦结合,AI 的角色就会从回答问题的工具,变成能参与科学探索的协作系统。对我来说,这篇文章最有价值的地方正在这里。它不是在空谈远景,而是在给出一条已经能看到前后脉络的路线。
模型层这周也很热闹。Gemini Embedding 2 是 Google 发布的首个原生多模态嵌入模型,把文本、图像、音频、视频和文档统一到同一个向量空间,支持 100 多种语言,还支持 MRL 灵活维度压缩,可以在精度和存储之间动态取舍。对正在搭建多模态 RAG 系统的团队来说,这是个很实用的底层升级。
NVIDIA Nemotron 3 Super 则瞄准了另一个缺口:专门为智能体推理优化的开源基础模型。120B 参数、1M 超长上下文、Mamba-Transformer 混合架构带来 5 倍吞吐量提升,对需要在本地运行复杂多 Agent 任务的团队,是个值得关注的选择。
两项面向 Agent 的组件研究也很值得收藏。通义实验室开源的 Mobile-Agent-v3.5 通过混合数据飞轮与强化学习,首次在桌面、移动和浏览器三个平台上统一了 GUI 自动化能力,在 20 多个基准上达到开源最优。微软研究院的 PlugMem 则解决了长会话 Agent 的一个老问题:记忆臃肿。它把 Agent 的交互历史提炼成结构化事实和可复用技能,用更少的 Token 保留更有用的决策信息。
这两项工作让我更强烈地感觉到,Agent 基础设施正在变成熟。它不再只是大模型能力的展示,而是开始变成能被真实工程复用的组件。
解构智能体:一理一实
本周有两篇内容放在一起读,特别有意思。一篇讲原理,一篇讲实战。
李宏毅教授的解剖小龙虾视频是本周我最推荐的学习资源之一。他把 AI Agent 讲得非常清楚,核心观点也很直接:Agent 不是什么神秘概念,本质上就是一套由系统提示词、工具调用、记忆机制和 Sub-Agent 协作拼起来的系统。
他把 Agent 的运作拆成四个层次。第一层是身份认知:系统提示词决定了 Agent 是谁、能做什么、边界在哪里。第二层是记忆管理:RAG 检索外部知识,对话压缩突破上下文上限,让 Agent 能持续处理长任务。第三层是持续运行:心跳机制让 Agent 保持 24 小时自主运行,不依赖人工触发。第四层是任务分解:Sub-Agent 在隔离沙箱里并行处理独立子任务,主 Agent 负责协调和整合。
这四层叠起来,就构成了 OpenClaw 这类系统的运作逻辑。这个视频最有价值的地方,是它先帮你建立心智模型,再去谈具体工具怎么用。现在关于 Agent 的讨论已经很多了,很多人真正缺的不是更多技巧,而是一张能看清全局的地图。
腾讯技术工程的 OpenClaw 实战指南则提供了从地图到现场的路径。文章从硬件选型讲到多 Agent 协同架构,展示了每日论文抓取、ComfyUI 图像生成等真实落地案例,也给了一个很实用的安全提醒:越追求高自动化,越要按数据全开的最坏情况来估算风险,边界先设好,再放行。
两篇放在一起看,是理解 OpenClaw 体系很好的入口。前者帮你建立框架,后者告诉你怎么落地。
Claude Code 工程的系统化进阶

本周关于 Claude Code 工程实践的内容密度很高,我挑几篇真正有系统性的。
Tw93 深度使用 Claude Code 半年后写出的这篇分析,是我目前见过对 Claude Code 拆解最系统的中文文章之一。他把整套系统分成六层:CLAUDE.md 定义长期上下文,Tools/MCP 提供动作能力,Skills 注入按需工作流,Hooks 做强制拦截,Subagents 负责隔离执行,Verifiers 完成验证闭环。核心洞察是,Agent 的失控往往不来自模型能力不足,而来自上下文污染、工具冗余和缺乏确定性约束。
这个框架里有几个细节值得展开。Hooks 是强制拦截层,在 AI 执行动作之前插入确定性检查,相当于给 Agent 装了个安全阀。不管模型多强,有些操作就是不能绕过人工确认。Verifiers 是验证闭环层,让 AI 不只是执行,还要验证自己的执行结果是否达标。这两层合在一起,解决了 Agent 系统里最难处理的两个问题:越权和自欺。
他的另一个判断我也很认同:上下文工程比提示词工程更重要。好的 CLAUDE.md 不是说明书,更像项目的运行边界和协作共识。它要告诉 AI 目标是什么、约束在哪里、什么时候必须停下来问人。这部分做扎实了,模型之间的差异反而没那么关键。
这个框架配上 HackerNoon 上的可扩展性三角一起读会更完整。这篇文章给了一个清晰的决策框架:MCP 负责动态数据交互,Subagents 负责任务隔离与模型路由,Skills 负责静态知识注入。三者边界清晰,过度设计是最大的工程病。作者举的一个例子很到位:把静态文档塞进 MCP,或者让 Skills 去查数据库,本质上都是工具放错了位置。
OpenAI 的 Build Hour 视频从官方视角展示了这套方法论在 Codex 上的实践。他们提出了 Harness Engineering 的 7 个易读性指标,核心主张是把 agent.md 规则嵌进代码库,让 AI 能独立完成 PR 交付,而不是全程靠人盯着。
得物技术的 Spec Coding 实战报告则用数据印证了这条路的价值:10 天、2754 次真实工具调用,三层规范体系带来 36% 的效率提升。文章难得的地方在于,它也客观记录了失效边界,在复杂 CI 环境和隐性依赖场景下,AI 会在哪里出错。这份诚实反而让这篇实战报告更有参考价值。
说到这里,企业级落地还有一个很值得单独拿出来看的点:Code Review。

快手的智能 Code Review 三阶进化则提供了企业规模验证。从采纳率 7.9% 的纯 LLM 启发式,到积累 1100 条硬性规则的规则确定性阶段,再到能感知仓库级上下文、主动识别关联改动的 Agentic 自主决策,最终采纳率做到了 54%。最打动我的细节,不是模型本身,而是他们愿意把 1100 条确定性规则这种苦活做扎实。AI 幻觉真要压下来,很多时候靠的不是更强的模型,而是更硬的工程约束。
编程智能体正在重塑工程、产品与设计

当构建门槛继续下降,真正稀缺的会是什么?本周几篇文章合在一起,给了我一个比较明确的答案。
LangChain 的这篇文章把这个问题说得最直白。随着代码实现成本快速下降,软件开发的瓶颈正在从实现转向评审和系统思维。变化不只是效率提升,而是整个工作流在重排:PRD 的位置在变,原型驱动的迭代越来越靠前。工程师不一定先从需求文档开始,而是先让 AI 跑出一个能点击的原型,再围绕原型对齐认知。
这会带来角色分化。未来的专业人才,大概率会越来越分成两类:一类能直接动手构建、端到端交付;另一类更擅长架构判断和质量把控,能识别 AI 生成物里那些不容易一眼看出来的问题。但两类人都绕不过去一件事:产品感。原型到底对不对,体验顺不顺,方向值不值得继续做,这个判断在 AI 可以大量生成代码之后,反而更重要了。
值得一提的是,OpenClaw 超越 React,成为 GitHub 历史上 Star 最多的项目,这本身就是个很强的信号。Founder Park 对 Product Hunt 上 500 多款相关产品的梳理也说明,一条自下而上长出来的生态链已经有了雏形。不过我更倾向把它理解成基础设施到位的信号,而不是终局。
YC 设计专家的视频复盘指出了一个越来越常见的副作用:Vibe Coded 网站开始长得越来越像,都是熟悉的淡入动画、模板化仪表盘和没什么辨识度的视觉语言。AI 是执行杠杆,不是品味替代品。Elys 创始人 Tristan 的对话也从 AI 社交产品的角度呼应了这一点:真正难复制的,不只是模型能力,而是一个产品如何积累记忆、组织 context,并把这种长期关系沉淀下来。当所有人都能更快地做东西时,知道该做什么、为什么这样做,会变得更值钱。
宏观格局:五层蛋糕与记忆护城河
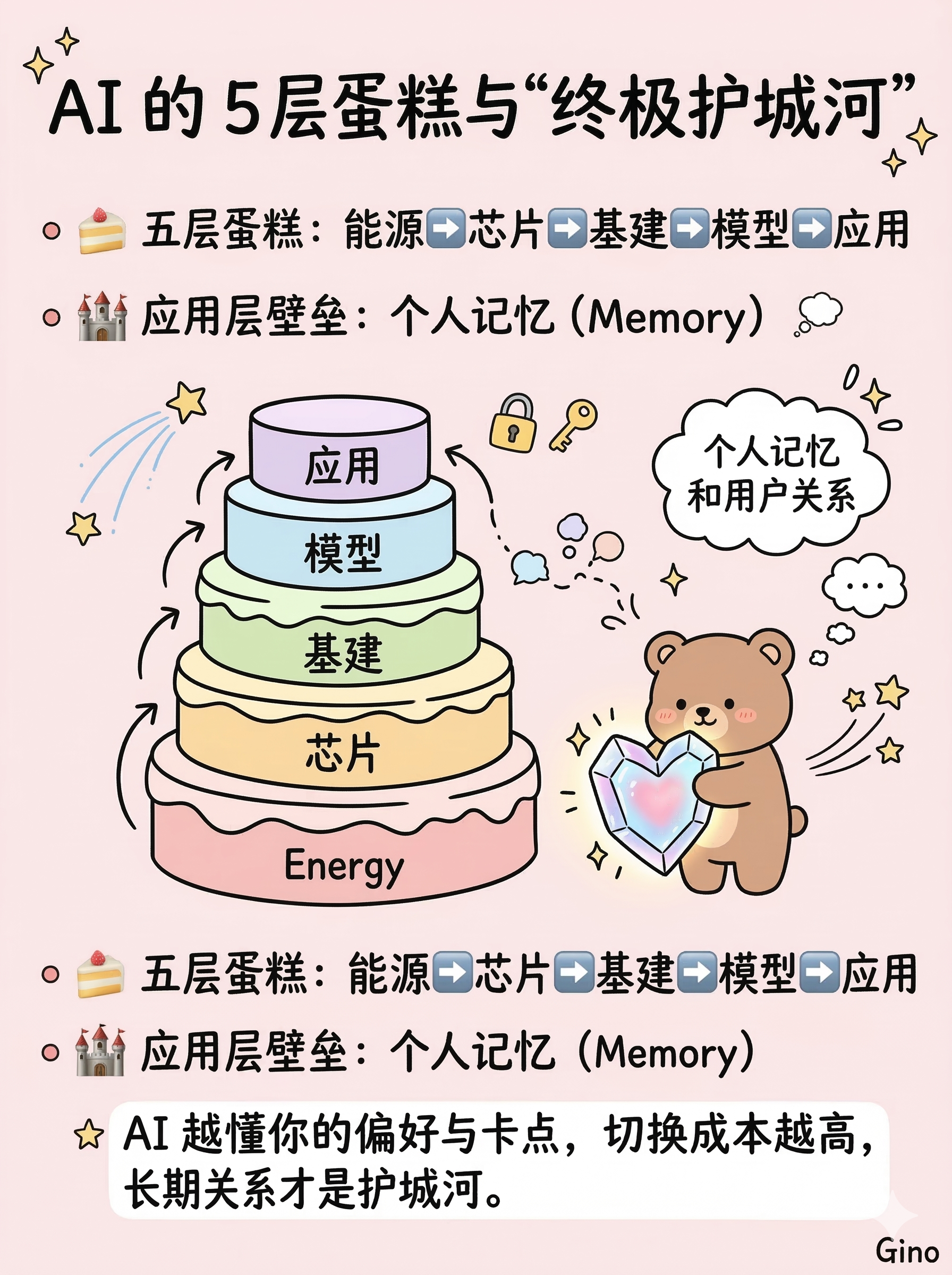
黄仁勋在署名长文里把 AI 拆成了五层蛋糕:能源层、芯片层、基础设施层、模型层、应用层。他的判断很直接:AI 更像一条完整产业链,而不只是一个软件产品。DeepSeek-R1 这样的开源模型,会继续充当供给侧的催化剂。它一边压低应用层门槛,一边把底层算力和基础设施需求重新拉起来。
a16z 的消费级 AI 应用百强榜则给了应用层一个最新切面。ChatGPT 的统治地位依然很稳,Claude 和 Gemini 也分别在专业和创意场景里占住了位置。
我觉得这里最值得盯住的,不是榜单名次,而是另一个变化:个人记忆正在变成新的竞争点。当模型能力越来越接近,谁更懂用户是谁、偏好是什么、做过哪些决定、现在卡在哪,谁就更容易建立长期优势。这更像关系积累,而不是单点功能。AI 用得越久,越懂你,切换成本也就越高。从这个角度看,很多 AI 产品现在在记忆能力上的投入,不只是功能迭代,也是在提前锁定未来的用户关系。
这两篇宏观内容,和另外两篇放在一起看,会更有意思。写给 AI 创业者的慷慨、残酷与迷雾用印刷机、电动机和云计算三段历史,推演出一个反复出现的规律:当核心能力被商品化,竞争就会从能不能做出来,转向做什么、为谁做、以及怎么被看见。当 AI 编程能力开始变成人人可用的工具,架构判断、产品直觉和用户理解,就成了新的稀缺资源。
屠龙之术的年度总结播客则补上了更宏观的数据面:70 页 PPT 回顾 2026 年 Q1 的中美 AI 格局,从算力叙事到 Agent 革命,再到中国模型厂商估值变化。如果你想快速把这段时间的行业变化过一遍,这期内容值得听。
基建时代的一点感想
读完这期内容,我反复在想一个问题:为什么大家都开始谈基建?
表面原因不难理解:OpenClaw 生态在扩张,模型在迭代,工具在成熟,大家都在往地基里补东西。但再往下一层看,基建时代也意味着执行力本身没那么稀缺了。当 Agent 可以 24 小时跑任务,当 Spec Coding 把效率提升 36%,当 AI 代码评审采纳率从 7.9% 提到 54%,执行差距会被越来越快地抹平。最后真正拉开差距的,往往是你能不能把正确的约束、知识和判断标准,稳定地交给 AI。
这也是为什么 Tw93 的六层架构让我觉得很有价值。它不是在教你怎么用 Claude Code,而是在帮你设计一套能让 AI 稳定工作的系统。快手 Code Review 的演进路径值得借鉴,也不是因为他们选了什么模型,而是因为他们把 1100 条规则这种脏活累活真正做完了。屠龙之术年度总结里最打动我的,也不是哪个模型分数更高,而是那句知识驱动比工具驱动走得更远。
这和我这周搭个人内容工作流时的感受几乎一模一样。把工具串成系统不算难,难的是把系统调到真正顺手。顺手的系统需要清晰的意图、合理的约束和持续的反馈校准。这三件事,我现在看都还得由人来做。
以上就是本期的核心内容。本期完整的 20 篇精选文章,可以在 BestBlogs.dev 上查看。
保持好奇,我们下周见。
